The Magnet Forensics Weekly CTF has been running since October and sets one question each week using an image that changes each month. The October questions were based on an Android filesystem dump. November’s image is Linux, more specifically a Hadoop cluster comprising of three E01 files. The images were created by Ali Hadi as part of his OSDFCon 2019 Linux Forensics workshop; the November CTF questions are based on Case 2, which can be downloaded here.
You can find my other Magnet Weekly CTF write-ups here.
Had-A-Loop Around the Block (75 points)
What is the original filename for block 1073741825?
New month, new image. I’ve done some Linux forensics before but never anything involving Hadoop. And this question is worth 75 points. Week 3 was only worth 40 so this gives an indication that it’s going to be a long one!
The Case 2 image set is comprised of three hosts:
- HDFS-Master
- HDFS-Slave1
- HDFS-Slave2
I started with HDFS-Master.E01 just because it seemed like a sensible place to begin. The first thing to do is mount the disk image and see what we have.
Part 1 – Mounting E01 files using SIFT Workstation
Most Linux forensics tools are happiest when they are working with raw disk images. The fact we have Expert Witness Format (E01) files complicates things a little, but not too much.
I like to use free or open-source tools as far as possible for CTFs so we are going to mount the image as a loopback device using ewfmount and tools from The Sleuthkit – all available in the SANS SIFT virtual machine.
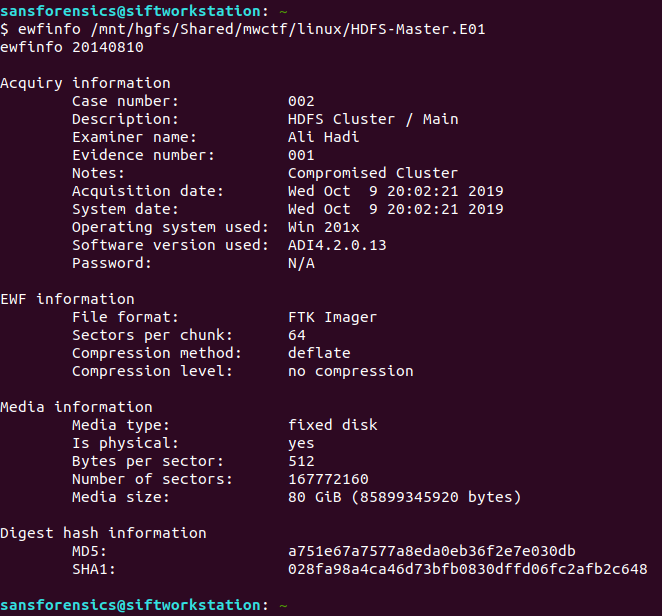
One of the advantages of E01 files is that they can also contain case metadata. We can view this metadata using the ewfinfo tool.
ewfinfo /mnt/hgfs/Shared/mwctf/linux/HDFS-Master.E01
Before we create the loopback device we need to get our E01 file into something resembling a raw disk image. We could convert the E01 to raw using ewfexport but that takes time and expands our image to the full 80GB disk. Instead, we will use ewfmount to create something the standard Linux tools can work with.
sudo ewfmount /mnt/hgfs/Shared/mwctf/linux/HDFS-Master.E01 /mnt/ewf

efwmount creates a read-only, virtual raw disk image located at /mnt/ewf/ewf1. The next thing to do is check on the geometry of the disk. I used mmls from The Sleuthkit to dump the partition table; we’ll need this data for the next step.
(From here on I had to sudo to a root shell due to the permissions that ewfmount left me with)
sudo -s # mmls /mnt/ewf/ewf1
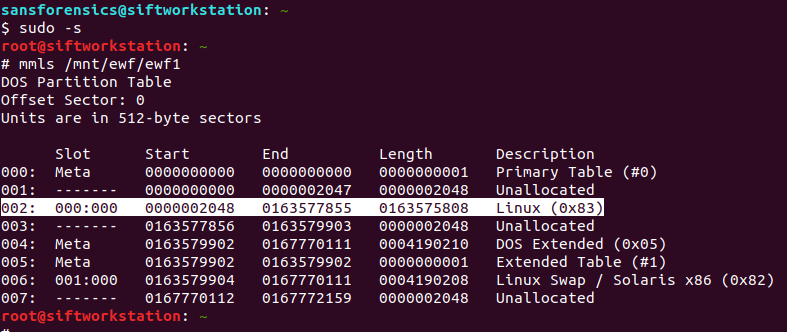
Partition 002 is the one we are interested in. Its description tells us it is Linux ext2/3/4 and the length means it is the largest single partition on the disk. The part we need to take note of for now is the Start sector offset: 2048. We will use this later to mount the partition. First though, let’s get some more information about the filesystem on the partition.
# fsstat -o 2048 /mnt/ewf/ewf1 | tee /home/sansforensics/mwctf/fsstat-2048.out
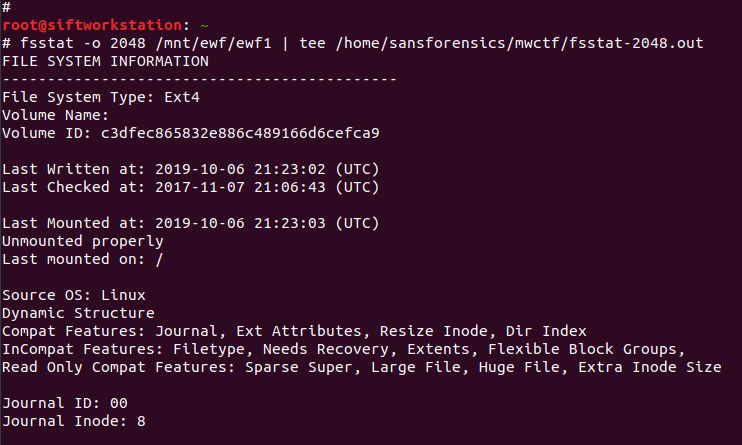
The fsstat command gives us a lot of information that might be useful later on, so I used tee to save the output to a file. The output confirms that we are dealing with an ext4 filesystem which, helpfully, was unmounted correctly! Now, we can move on and create the loopback device which will then allow us to mount the filesystem.
# losetup --read-only --offset $((2048*512)) /dev/loop20 /mnt/ewf/ewf1 # file -s /dev/loop20

This step gave me a lot of problems relating to the loop device being “unavailable”; losetup should be smart enough to use the next available device without prompting, but eventually I found that if I set the device myself (/dev/loop20, in my case) the command succeeded. The other aspects to note are that I created the loopback device as read-only – ewfmount already created a read-only device for us, but practice safe mounting – and that the offset value is the sector offset from mmls (2048) multiplied by the sector size in bytes (512).
Now we can move on to the final stage of preparation and actually mount the filesystem.
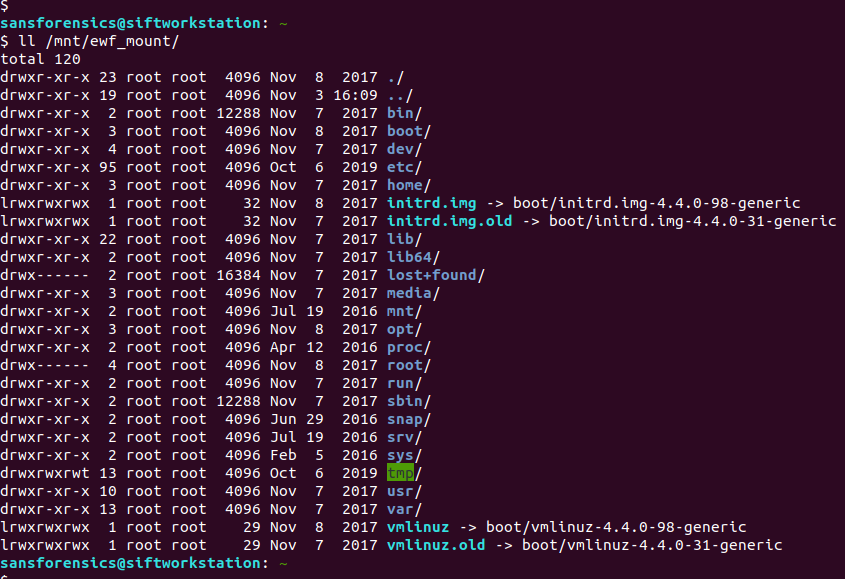
# mount -o ro,noload,noexec /dev/loop20 /mnt/ewf_mount/
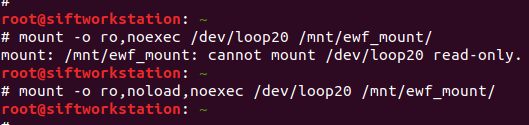
I also ran into a problem with my initial attempt to mount the filesystem. I suspect this was because the journal was in need of recovery (as per the file -s output above). Adding the noload option tells the filesystem driver to ignore the journal errors, and allows us mount the filesystem successfully! Again, read-only.
Part 2 – ext4 Block Analysis
Now we have the filesystem mounted we can get going on the analysis. The question asks for the filename for block 1073741825. My first thought was the ext4 block. I have recovered deleted files from ext4 in the past by working from the inode via the block group, to the raw blocks on disk (Hal Pomeranz gave an excellent webcast covering exactly this scenario), maybe I can work backwards from the block number?
But that block number looks awfully large, especially for an 80GB disk. Let’s take another look at our saved fsstat output.
cat mwctf/fsstat-2048.out | grep -A 6 "CONTENT INFORMATION"
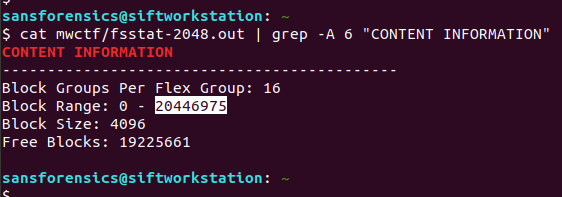
The question asks about block number 1,073,741,825 but the filesystem only contains 20,446,976 blocks. Okay, so we are not looking for an ext4 block. But, this is a Hadoop cluster. How does Hadoop store data?
Part 3 – Investigating Hadoop
The best resource I found to get a quick overview of performing forensic analysis of Hadoop (rather than using Hadoop to perform analysis) was Kevvie Fowler’s helpfully titled Hadoop Forensics presentation from the 2016 SANS DFIR Summit. Armed with this and some Googling, I located the Hadoop installation and data in the following directory:
/mnt/ewf_mount/usr/local/hadoop
I was looking for the namenode location, which hold the fsimage files, which in turn, hold the metadata we are looking for. I found this by examining the hdfs-site.xml configuration file:
cat /mnt/ewf_mount/usr/local/hadoop/etc/hadoop/hdfs-site.xml
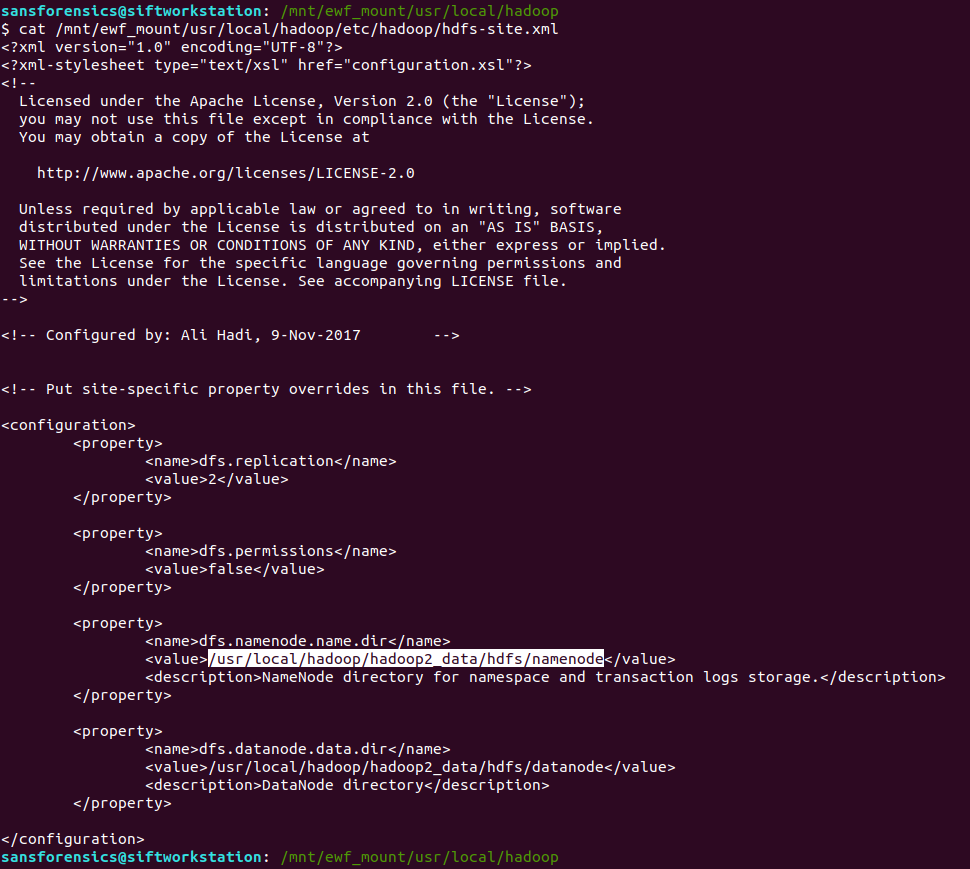
Looking under the namenode directory we find the fsimage files. The edits_ files can be thought of as being like transaction logs; best-practice would be to merge these before doing the analysis but for our needs this wasn’t necessary.
ll /mnt/ewf_mount/usr/local/hadoop/hadoop2_data/hdfs/namenode/current
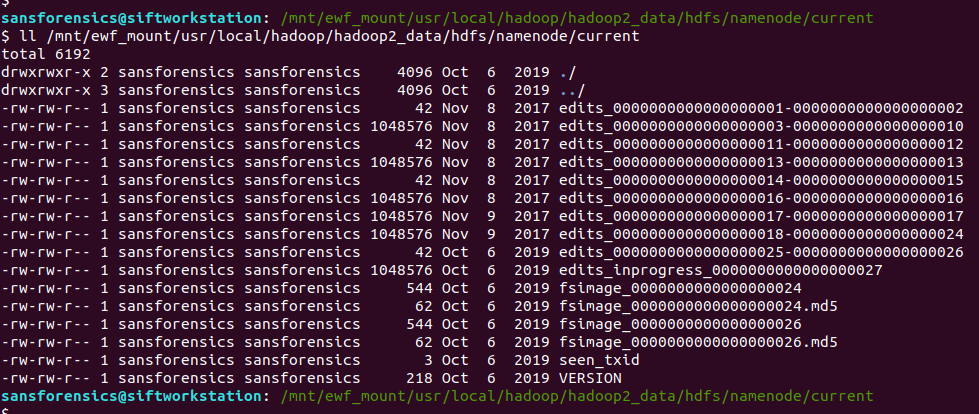
Now that we have found the fsimage files, we need to get intelligible data out of them. Hadoop makes heavy use of a utility named hdfs. Among the many functions hdfs provides is the Offline Image Viewer (oiv) which can be used to parse the fsimage files and output something human-readable . That sounds exactly what we are after, the next problem is how to run it!
I don’t have Hadoop on my SIFT VM and installing it looks a bit fiddly, but we have a disk image from a (presumably) working Hadoop installation so maybe we can use that instead?
ll /mnt/ewf_mount/usr/local/hadoop/bin/
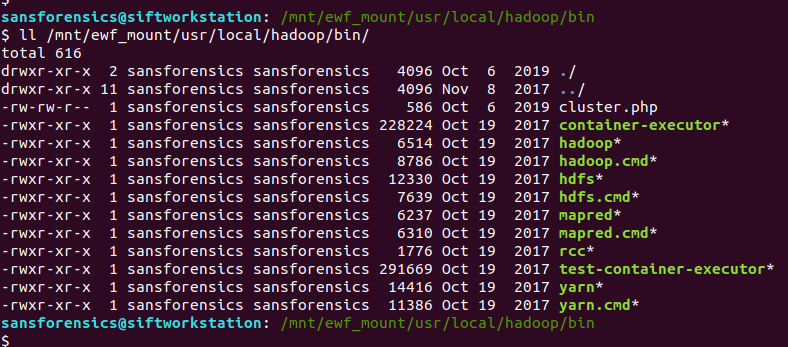
This is where things get a bit hacky. I mounted the filesystem using the noexec option as a protection against accidentally executing scripts and binaries from the disk image, but now that’s exactly what I want to do, so I unmounted and remounted the filesystem to allow this.
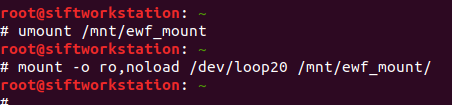
# umount /mnt/ewf_mount # mount -o ro,noload /dev/loop20 /mnt/ewf_mount/
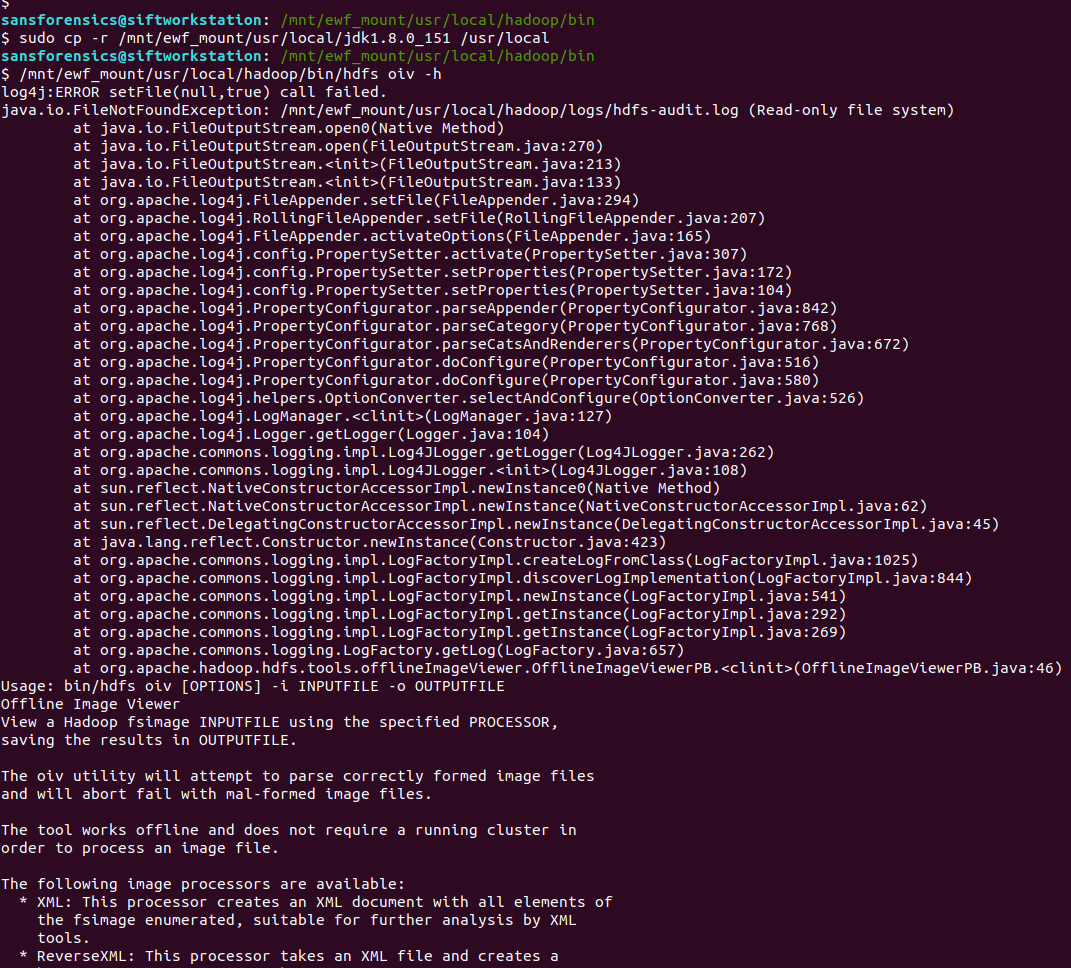
However, the Offline Image Viewer (hdfs oiv) throws an error because the Java path is incorrect.
/mnt/ewf_mount/usr/local/hadoop/bin/hdfs oiv -h

The Offline Image Viewer is looking for Java under /usr/local/ instead of /mnt/ewf_mount/usr/local/ taking the mounted disk image into account. I tried inspecting the script and exporting a new $JAVA_HOME environment variable, but it seems the Offline Image Viewer is taking the variable from a file, and as we are working on a read-only filesystem, we can’t easily change that. So instead of fighting to get the Offline Image Viewer to recognise an updated path, I simply copied the Java installation from the image to my native /usr/local directory and tried again.
sudo cp -r /mnt/ewf_mount/usr/local/jdk1.8.0_151 /usr/local /mnt/ewf_mount/usr/local/hadoop/bin/hdfs oiv -h
Better! We have an exception because hdfs cannot write to its log file on a read-only filesystem, but the Offline Image Viewer runs! Let’s see if it can extract anything from the imagefs files we identified earlier.
/mnt/ewf_mount/usr/local/hadoop/bin/hdfs oiv -i /mnt/ewf_mount/usr/local/hadoop/hadoop2_data/hdfs/namenode/current/fsimage_0000000000000000024 -o /home/sansforensics/mwctf/fsimage_24.xml -p XML
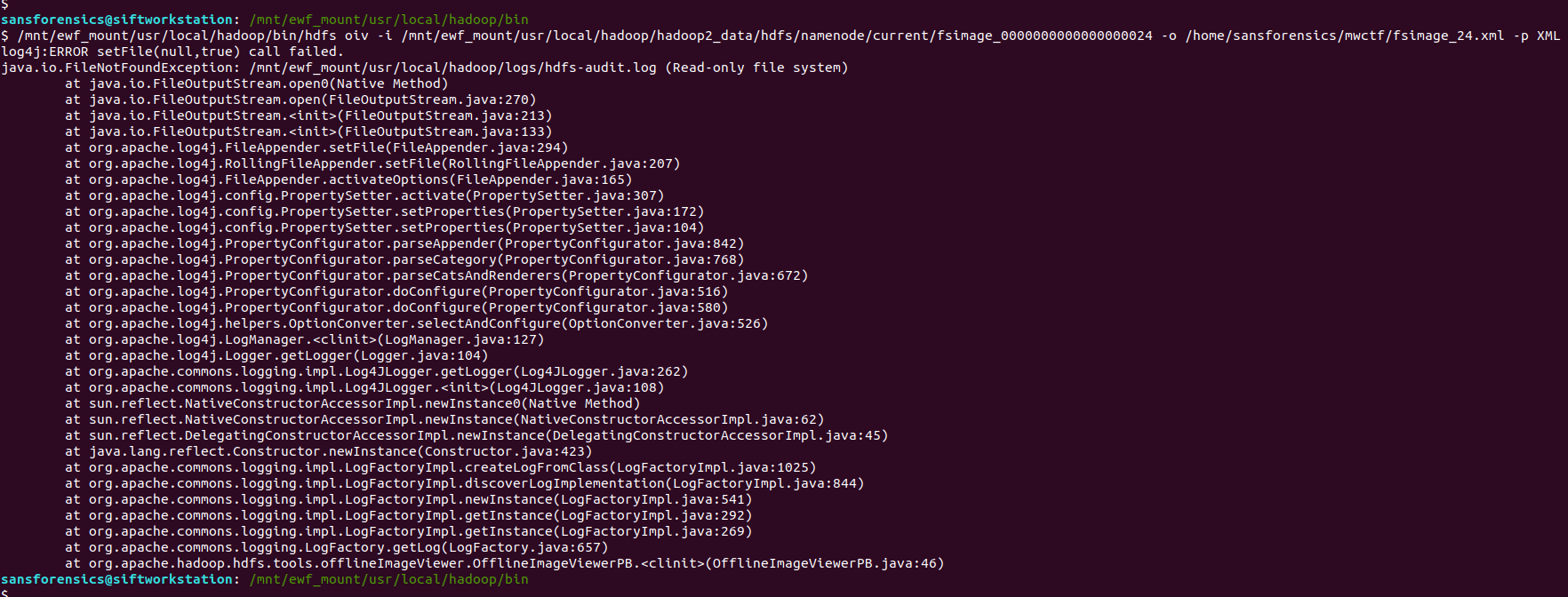
We have the same exception because of the read-only filesystem, but…
cat /home/sansforensics/mwctf/fsimage_24.xml
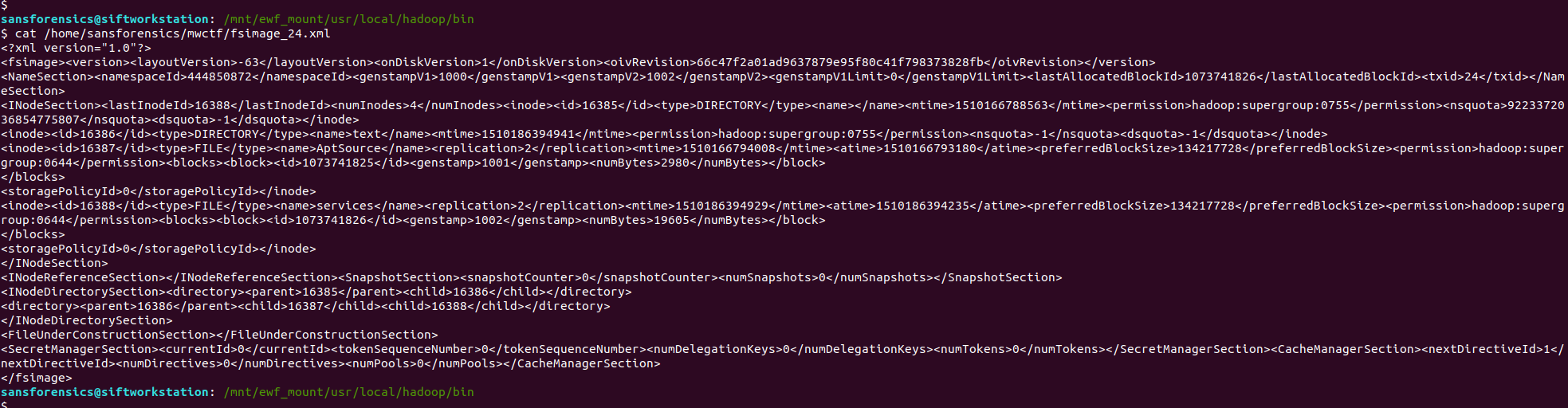
… we have an XML file! After making the XML look pretty and searching for the block number, we find our answer in the name tag.
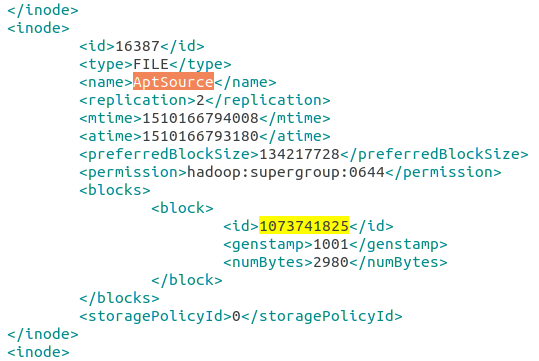
Week 5 done!
Flag
AptSource
Thanks for a very thorough walkthrough, including the difficulties and solutions. You are providing a great service for those of us learning on our own!