Back in January I began setting up a Kippo SSH honeypot on an old VPS that I wasn’t really using for anything else. As it was a spur-of-the-moment kind of thing I spent an hour or two making the Kippo SSH service look a bit more interesting (and less like Kippo) before hardening the real SSH service and promptly forgetting all about it.
Until last week when I logged into the VPS for the first time in close to six months, noticed a suspiciously large number of SSH connections, and after a brief moment of panic, realised I had six months of honeypot data to play with! The excitement didn’t last very long.
Kippo Graph
There’s quite a lot of 3rd party development around Kippo, and one of the really nice projects is kippo-graph. Kippo-graph was written by @ikoniaris and is a collection of (mostly) PHP files which extract data from Kippo’s MySQL database, and generate and display lots of nice graphs, charts, and statistics showing what’s been happening on the honeypot. It’s exactly what I needed! The only problem was that in my haste to get Kippo up and running I’d forgotten to enable MySQL logging…
6,732 Text Files
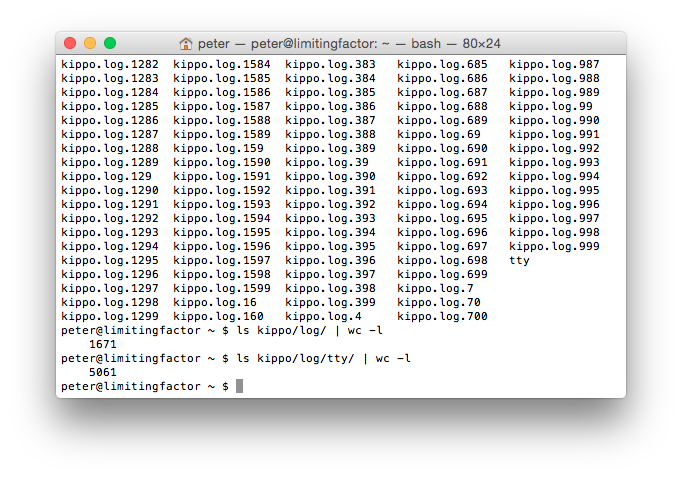
Instead of a nice database I was left with roughly 6,700 text files detailing every IP address, password attempt, and console command issued over a six month period. Analysing them manually obviously wasn’t going to work, so my only other option was to parse the text files and build the database myself. While I could probably have taken a few days to throw something together in Python, a bit of searching pointed me at Ion’s blog about kippo-log2db. I was getting closer.
Kippo-log2db
Kippo-log2db is a Perl script by Jim Clausing (@jclausing) that parses the Kippo log files and creates a MySQL database following the original Kippo schema. After downloading the script and giving it the correct MySQL credentials, my initial attempts were met with a couple of recurring errors:
DBD::mysql::st fetchrow_array failed: fetch() without execute() at ./kippo-log2db.pl line 98,
and
DBD::mysql::st execute failed: Column ‘sensor’ cannot be null at ./kippo-log2db.pl line 125,
The first of these errors appears to be due to the script trying to reference an empty set of results pulled from an earlier MySQL query. I’m not a Perl coder, and the script was adding records to the database, so I just let that one go. The second error was more concerning, referencing a database error as a result of trying to insert a null value into the “sensor” column. My main concern was that this indicated my logs were incomplete, or otherwise lacking values, but being too impatient to go digging through the log files I simply modified the database schema to allow null values in the “sessions” table. This is likely to have caused a few problems later on.
“This could take some time to complete”
Following the modifications I restarted the script and left it to run. Jim warns in his script that it might take some time; he’s not joking. I originally used an old 256MB Raspberry Pi to run the import but after running it overnight and seeing it had only completed 200 of the 1,600 log files, I moved the data to one of my dedicated boxes and restarted the process, even so, the import took a little over 3 days to complete but left me with the nice database I needed.
I quickly downloaded and configured kippo-graph, then fired up a web browser to see what it made of my efforts.
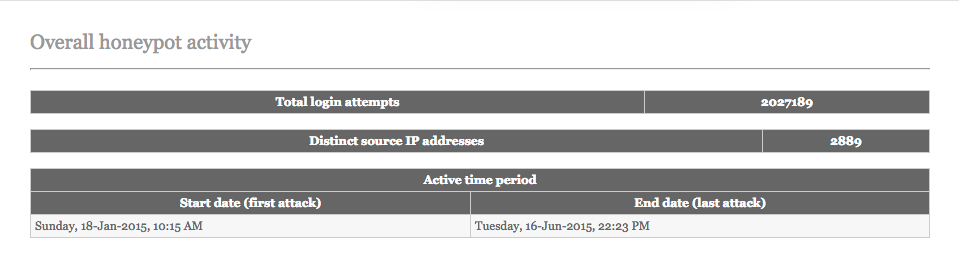
2,027,189 login attempts! The errors I encountered during the database creation seem to have propagated through in places. For example, kippo-graph seems to think that every single login attempt failed.
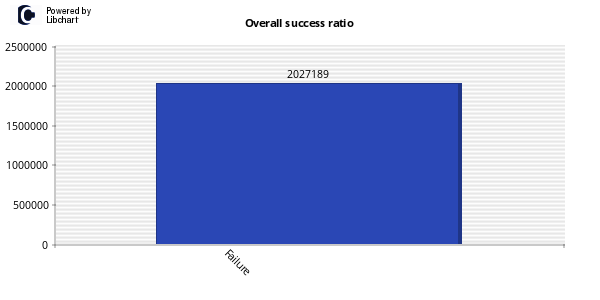 Other charts are more useful though, and the kippo-input and kippo-playlog functions are simply brilliant. The process didn’t work perfectly, but well enough that I should be able to get something interesting out of my data.
Other charts are more useful though, and the kippo-input and kippo-playlog functions are simply brilliant. The process didn’t work perfectly, but well enough that I should be able to get something interesting out of my data.
Of course, this could all have been avoided if I’d remembered to enable MySQL logging in the first place!